Mercato dei dataset di training per l'AI: analisi attuale e previsioni (2024-2032)
Enfasi su Tipo (Testo, Audio, Immagine, Video e Altro (Sensore e Geo)); Modalità di Implementazione (Cloud e On-Premise); Utente Finale (IT e Telecomunicazioni, Retail e Beni di Consumo, Sanità, Automotive, BFSI e Altro (Governo e Produzione)); e Regione/Paese
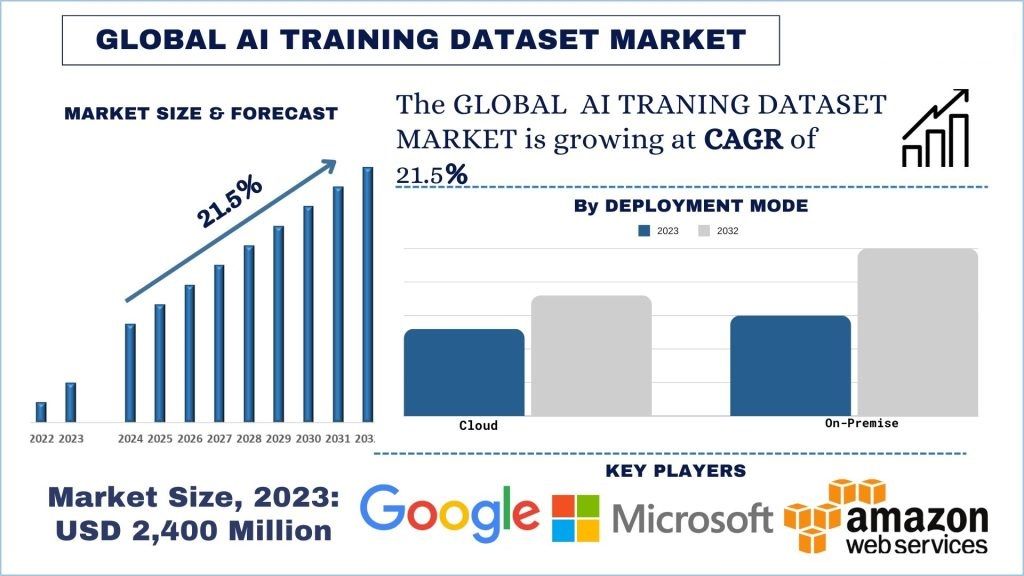
Dimensioni e previsioni del mercato dei dataset di addestramento AI
Il mercato dei dataset di addestramento AI è stato valutato a 2.400 milioni di dollari USA e si prevede che crescerà a un forte CAGR di circa il 21,5% durante il periodo di previsione (2024-2032) grazie alla crescente proliferazione dello sviluppo e dell'implementazione di applicazioni AI e ML.
Analisi del mercato dei dataset di addestramento AI
I dataset di addestramento AI sono i dati fondamentali utilizzati per addestrare e sviluppare modelli di machine learning e intelligenza artificiale. Questi dataset sono costituiti da esempi etichettati che i modelli AI utilizzano per apprendere modelli e relazioni ed effettuare previsioni accurate. I dataset vengono raccolti da varie fonti come database, siti web, articoli, trascrizioni video, social media e altre fonti di dati pertinenti. L'obiettivo è quello di raccogliere un insieme di dati diversificato e rappresentativo. I dati grezzi vengono accuratamente etichettati e annotati per fornire al modello AI informazioni accurate da cui apprendere. Ciò comporta la categorizzazione, l'etichettatura e la descrizione dei dati.

Il campo dell'Intelligenza Artificiale (AI) ha assistito a una crescita e a progressi senza precedenti negli ultimi anni, con applicazioni e tecnologie basate sull'AI che sono diventate sempre più prevalenti in vari settori. Questa rapida espansione dell'AI ha portato a un corrispondente aumento della domanda di dataset di addestramento AI di alta qualità, diversificati e completi per alimentare questi sistemi avanzati. Inoltre, la crescente adozione di tecnologie basate sull'AI in settori come l'assistenza sanitaria, la finanza, l'e-commerce e i trasporti è stata un importante motore della domanda di dataset di addestramento AI. Poiché le aziende e le organizzazioni cercano di sfruttare la potenza dell'AI per migliorare le proprie operazioni, migliorare il processo decisionale e offrire esperienze personalizzate, la necessità di dataset robusti, affidabili e diversificati per addestrare questi modelli AI è salita alle stelle. Inoltre, la crescente popolarità e l'adozione diffusa degli algoritmi di machine learning (ML) e deep learning (DL) sono stati un fattore significativo nell'aumento della domanda di dataset di addestramento AI. Queste tecniche avanzate si basano su vaste quantità di dati per addestrare i loro modelli, apprendere i modelli ed effettuare previsioni accurate. Ad esempio, in Corea del Sud, i dati dei clienti sono emersi come la principale fonte di informazioni per l'addestramento dei modelli di intelligenza artificiale (AI) nel 2022, come dichiarato da quasi il 70% delle aziende intervistate. Inoltre, circa il 62% degli intervistati ha indicato l'utilizzo di dati interni per l'addestramento dei propri modelli AI.
Tendenze del mercato dei dataset di addestramento AI
Questa sezione analizza le principali tendenze del mercato che stanno influenzando i vari segmenti del mercato dei dataset di addestramento AI, come identificate dal nostro team di esperti di ricerca.
I dataset in formato testo sono attualmente utilizzati in modo preponderante per l'addestramento di modelli AI e ML e generano la maggior parte delle entrate per il settore dei dataset di addestramento AI.
I dati di testo sono onnipresenti nell'era digitale, con vaste quantità di informazioni disponibili su Internet, in libri, articoli, social media e varie altre fonti. I dataset di testo sono generalmente più facili da raccogliere, archiviare ed elaborare rispetto ad altri tipi di dati, come audio o video. Inoltre, i dati di testo possono essere utilizzati per addestrare un'ampia gamma di modelli AI e ML, inclusi i modelli di elaborazione del linguaggio naturale (NLP) per attività come l'analisi del sentiment, la classificazione del testo, la generazione del linguaggio e la traduzione automatica. I dati di testo possono anche essere utilizzati per addestrare modelli per attività che vanno oltre l'NLP, come la sintesi di documenti, il recupero di informazioni e persino attività di analisi di immagini e video. La versatilità dei dati di testo consente lo sviluppo di una gamma diversificata di applicazioni AI e ML, da chatbot e assistenti virtuali a sistemi di raccomandazione di contenuti e strumenti di scrittura automatizzati. Inoltre, i dati di testo sono generalmente meno intensivi dal punto di vista computazionale da elaborare rispetto ad altri tipi di dati, come immagini ad alta risoluzione o video, che richiedono hardware più potente e maggiori risorse computazionali. Ciò rende i modelli AI e ML basati su testo più accessibili e fattibili da sviluppare e implementare, soprattutto su dispositivi con risorse limitate o in scenari con potenza di calcolo limitata. Fattori come questi stanno favorendo un ambiente favorevole, guidando l'impennata della domanda di dataset di testo per l'addestramento di vari modelli AI e ML.
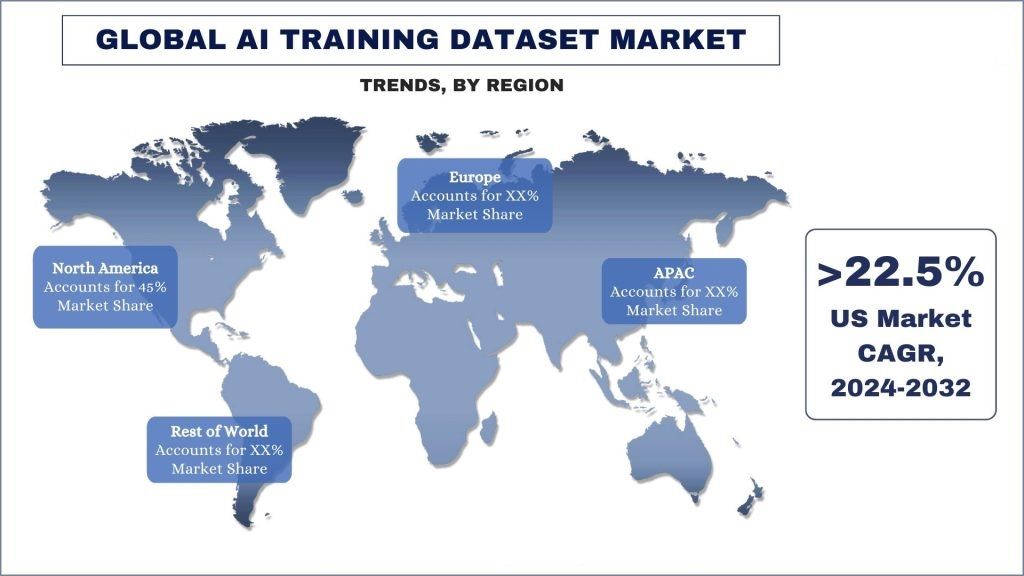
Il Nord America emerge come il mercato in più rapida crescita e rappresenta la maggior parte del mercato globale dei dataset di addestramento AI.
Il Nord America è emerso come uno dei mercati più grandi e in più rapida crescita per i dataset di addestramento AI. Gli Stati Uniti ospitano alcune delle principali università di ricerca del mondo, come Stanford, il MIT e la Carnegie Mellon, che hanno compiuto progressi significativi nella ricerca sull'AI e sull'ML. Inoltre, importanti aziende tecnologiche, tra cui Google, Microsoft e Amazon, hanno creato laboratori di ricerca sull'AI all'avanguardia in Nord America, promuovendo ulteriormente l'innovazione e i progressi nel settore. Inoltre, il governo degli Stati Uniti ha riconosciuto l'importanza strategica dell'AI e ha investito ingenti somme a sostegno della ricerca e dello sviluppo attraverso iniziative come la National Artificial Intelligence Initiative. Inoltre, le principali aziende tecnologiche del Nord America hanno investito attivamente nella formazione e nella fidelizzazione dei migliori talenti AI e ML, creando un ciclo di auto-rafforzamento di innovazione e crescita. Infine, il Nord America, in particolare gli Stati Uniti, ospita un fiorente ecosistema di venture capital che ha investito miliardi di dollari in startup e aziende AI e ML. La presenza di importanti centri tecnologici, come la Silicon Valley, Boston e New York, ha facilitato il flusso di capitali di investimento nel settore dell'AI e dell'ML. Ad esempio, nel 2023, secondo i dati di S&P Global Market Intelligence, gli investimenti in aziende di AI generativa hanno visto un aumento significativo, superando il calo dell'attività complessiva di M&A. Le società di private equity hanno investito 2,18 miliardi di dollari nell'AI generativa, raddoppiando il totale dell'anno precedente. Questa impennata di capitale si è verificata in un contesto di diminuzione delle transazioni di M&A sostenute da private equity in tutti i settori nel 2023. Fattori come questi hanno reso il Nord America una forza predominante nel settore dell'AI e dell'ML, aumentando di conseguenza la domanda di servizi di dataset di addestramento AI per supportare questo tasso di crescita senza precedenti del settore dell'AI.
Panoramica del settore dei dataset di addestramento AI
Il mercato dei dataset di addestramento AI è competitivo e frammentato, con la presenza di diversi operatori di mercato globali e internazionali. Gli operatori chiave stanno adottando diverse strategie di crescita per migliorare la propria presenza sul mercato, come partnership, accordi, collaborazioni, lancio di nuovi prodotti, espansioni geografiche e fusioni e acquisizioni. Alcuni dei principali operatori che operano nel mercato sono Google, Microsoft, Amazon Web Services, Inc., IBM, Oracle, Alegion AI, Inc., TELUS International, Lionbridge Technologies, LLC, Samasource Impact Sourcing, Inc. e Appen Limited.
Novità sul mercato dei dataset di addestramento AI
- IBM ha presentato IBM Watsonx alla sua conferenza annuale Think il 9 maggio 2023. Questa innovativa piattaforma di AI e dati rivoluzionerà il modo in cui le aziende utilizzano l'AI avanzata, mantenendo al contempo l'affidabilità dei dati. Con IBM Watsonx, le organizzazioni possono accedere a una pila tecnologica completa per l'addestramento, la messa a punto e l'implementazione di modelli AI, inclusi modelli fondamentali e funzionalità di machine learning. Consente inoltre l'utilizzo senza interruzioni di dati affidabili in diversi ambienti cloud, garantendo velocità, governance e compatibilità.
- Baidu ha presentato nell'aprile 2024 una serie di nuovi strumenti AI progettati per consentire alle persone senza competenze di codifica di sviluppare chatbot basati sull'AI generativa su misura per scopi particolari. Questi chatbot possono successivamente essere incorporati in un sito web, nei risultati del motore di ricerca di Baidu o in altre piattaforme online.
Copertura del report di mercato sui dataset di addestramento AI
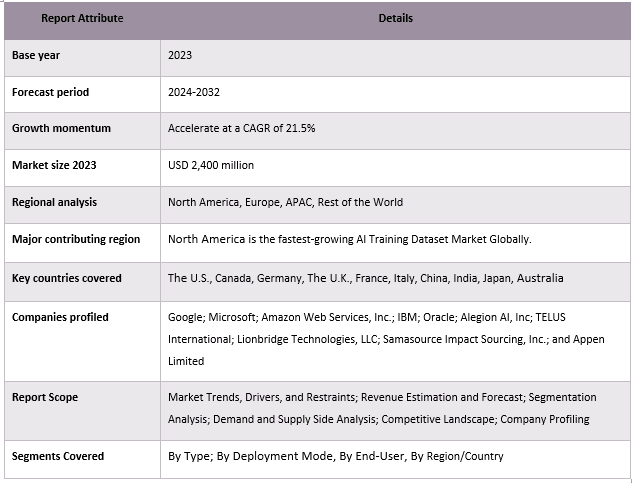
Copertura del report di mercato sui dataset di addestramento AI
Motivi per acquistare questo report:
- Lo studio include l'analisi delle dimensioni del mercato e delle previsioni convalidate da esperti chiave del settore autenticati.
- Il report presenta una rapida panoramica delle prestazioni complessive del settore a colpo d'occhio.
- Il report copre un'analisi approfondita dei principali concorrenti del settore con un focus primario sui principali dati finanziari aziendali, sui portafogli di prodotti, sulle strategie di espansione e sugli sviluppi recenti.
- Esame dettagliato dei driver, dei vincoli, delle tendenze chiave e delle opportunità prevalenti nel settore.
- Lo studio copre in modo completo il mercato attraverso diversi segmenti.
- Analisi approfondita a livello regionale del settore.
Opzioni di personalizzazione:
Il mercato globale dei dataset di addestramento AI può essere ulteriormente personalizzato in base alle esigenze o a qualsiasi altro segmento di mercato. Inoltre, UMI comprende che potresti avere le tue esigenze aziendali; quindi, sentiti libero di contattarci per ottenere un report che si adatti completamente alle tue esigenze.
Indice
Metodologia di ricerca per l'analisi del mercato dei dataset di addestramento AI (2024-2032)
L'analisi del mercato storico, la stima del mercato attuale e la previsione del mercato futuro del mercato globale dei dataset di addestramento AI sono stati i tre passaggi principali intrapresi per creare e analizzare l'adozione di dataset di addestramento AI nelle principali regioni a livello globale. È stata condotta un'esaustiva ricerca secondaria per raccogliere i dati storici del mercato e stimare le dimensioni del mercato attuale. In secondo luogo, per convalidare queste intuizioni, sono state prese in considerazione numerose scoperte e ipotesi. Inoltre, sono state condotte approfondite interviste primarie con esperti del settore lungo tutta la catena del valore del mercato globale dei dataset di addestramento AI. Dopo l'assunzione e la convalida dei dati di mercato attraverso interviste primarie, abbiamo impiegato un approccio top-down/bottom-up per prevedere le dimensioni complete del mercato. Successivamente, sono stati adottati metodi di scomposizione del mercato e di triangolazione dei dati per stimare e analizzare le dimensioni del mercato dei segmenti e sottosegmenti del settore. La metodologia dettagliata è spiegata di seguito:
Analisi delle dimensioni del mercato storico
Passaggio 1: Studio approfondito delle fonti secondarie:
È stato condotto uno studio secondario dettagliato per ottenere le dimensioni storiche del mercato dei dataset di addestramento AI attraverso fonti interne all'azienda come relazioni annuali e bilanci, presentazioni di performance, comunicati stampa, ecc. e fonti esterne tra cui riviste, notizie e articoli, pubblicazioni governative, pubblicazioni della concorrenza, relazioni di settore, database di terze parti e altre pubblicazioni credibili.
Passaggio 2: Segmentazione del mercato:
Dopo aver ottenuto le dimensioni storiche del mercato dei dataset di addestramento AI, abbiamo condotto un'analisi secondaria dettagliata per raccogliere informazioni storiche sul mercato e quote per diversi segmenti e sottosegmenti per le principali regioni. I principali segmenti inclusi nel rapporto sono tipo, modalità di implementazione e utente finale. Ulteriori analisi a livello di paese sono state condotte per valutare l'adozione complessiva dei modelli di test in quella regione.
Passaggio 3: Analisi dei fattori:
Dopo aver acquisito le dimensioni storiche del mercato di diversi segmenti e sottosegmenti, abbiamo condotto un'analisi dettagliata dei fattori per stimare le dimensioni attuali del mercato dei dataset di addestramento AI. Inoltre, abbiamo condotto un'analisi dei fattori utilizzando variabili dipendenti e indipendenti come il tipo, la modalità di implementazione e l'utente finale del mercato dei dataset di addestramento AI. È stata condotta un'analisi approfondita degli scenari di domanda e offerta considerando le principali partnership, fusioni e acquisizioni, espansione aziendale e lanci di prodotti nel settore del mercato dei dataset di addestramento AI in tutto il mondo.
Stima e previsione delle dimensioni del mercato attuale
Dimensionamento del mercato attuale: Sulla base delle informazioni utili ricavate dai 3 passaggi precedenti, siamo giunti alle dimensioni attuali del mercato, ai principali attori nel mercato globale dei dataset di addestramento AI e alle quote di mercato dei segmenti. Tutte le quote percentuali richieste e le scomposizioni del mercato sono state determinate utilizzando l'approccio secondario sopra menzionato e sono state verificate attraverso interviste primarie.
Stima e previsione: Per la stima e la previsione del mercato, sono stati assegnati pesi a diversi fattori tra cui driver e tendenze, vincoli e opportunità disponibili per le parti interessate. Dopo aver analizzato questi fattori, sono state applicate le tecniche di previsione pertinenti, ovvero l'approccio top-down/bottom-up, per arrivare alla previsione di mercato per il 2032 per diversi segmenti e sottosegmenti nei principali mercati a livello globale. La metodologia di ricerca adottata per stimare le dimensioni del mercato comprende:
- Le dimensioni del mercato del settore, in termini di fatturato (USD) e il tasso di adozione del mercato dei dataset di addestramento AI nei principali mercati a livello nazionale
- Tutte le quote percentuali, le divisioni e le scomposizioni dei segmenti e sottosegmenti di mercato
- I principali attori nel mercato globale dei dataset di addestramento AI in termini di prodotti offerti. Inoltre, le strategie di crescita adottate da questi attori per competere nel mercato in rapida crescita.
Convalida delle dimensioni e delle quote di mercato
Ricerca primaria: Sono state condotte interviste approfondite con i Key Opinion Leader (KOL), tra cui dirigenti di alto livello (CXO/VP, responsabile vendite, responsabile marketing, responsabile operativo, responsabile regionale, responsabile paese, ecc.) nelle principali regioni. I risultati della ricerca primaria sono stati quindi riassunti ed è stata eseguita un'analisi statistica per dimostrare l'ipotesi dichiarata. I contributi della ricerca primaria sono stati consolidati con i risultati secondari, trasformando così le informazioni in informazioni utili.
Suddivisione dei partecipanti primari nelle diverse regioni
Ingegneria del mercato
La tecnica di triangolazione dei dati è stata impiegata per completare la stima complessiva del mercato e per arrivare a numeri statistici precisi per ciascun segmento e sottosegmento del mercato globale dei dataset di addestramento AI. I dati sono stati suddivisi in diversi segmenti e sottosegmenti dopo aver studiato vari parametri e tendenze nelle aree del tipo, della modalità di implementazione e dell'utente finale nel mercato globale dei dataset di addestramento AI.
L'obiettivo principale dello studio sul mercato globale dei dataset di addestramento AI
Le tendenze attuali e future del mercato globale dei dataset di addestramento AI sono state individuate nello studio. Gli investitori possono ottenere informazioni strategiche per basare la loro discrezione per gli investimenti sull'analisi qualitativa e quantitativa eseguita nello studio. Le tendenze attuali e future del mercato hanno determinato l'attrattiva complessiva del mercato a livello regionale, fornendo una piattaforma per il partecipante industriale per sfruttare il mercato non sfruttato per beneficiare di un vantaggio di first-mover. Altri obiettivi quantitativi degli studi includono:
- Analizzare le dimensioni del mercato attuale e previsto del mercato dei dataset di addestramento AI in termini di valore (USD). Inoltre, analizzare le dimensioni del mercato attuale e previsto di diversi segmenti e sottosegmenti.
- I segmenti nello studio includono aree di tipo, modalità di implementazione e utente finale
- Definire e analizzare il quadro normativo per l'AI Training Dataset
- Analizzare la catena del valore coinvolta con la presenza di vari intermediari, insieme all'analisi dei comportamenti dei clienti e della concorrenza del settore
- Analizzare le dimensioni del mercato attuale e previsto del mercato dei dataset di addestramento AI per la regione principale
- I principali paesi delle regioni studiati nel rapporto includono Asia Pacifico, Europa, Nord America e il resto del mondo
- Profili aziendali del mercato dei dataset di addestramento AI e le strategie di crescita adottate dagli attori del mercato per sostenersi nel mercato in rapida crescita.
- Analisi approfondita a livello regionale del settore
Domande frequenti FAQ
D1: Qual è l'attuale dimensione del mercato e il potenziale di crescita del mercato globale dei dataset di addestramento AI?
Q2: Quali sono i fattori trainanti per la crescita del mercato globale dei dataset di addestramento per l'IA?
Q3: Quale segmento detiene la quota maggiore del mercato globale dei dataset di addestramento AI per utente finale?
Q4: Quali sono le tecnologie emergenti e le tendenze nel mercato globale dei dataset di training per l'IA?
Q5: Quale regione sarà il mercato dei dataset di addestramento AI globale con la crescita più rapida?
Q6: Chi sono i principali attori nel mercato globale dei set di dati per l'addestramento dell'IA?
Correlati Report
I clienti che hanno acquistato questo articolo hanno acquistato anche





Mercato dei servizi IT e BPO in India: Analisi attuale e Previsione (2026-2034)
Enfasi sul tipo di servizio (servizi IT, servizi BPO, servizi di ingegneria e R&D); tipo di outsourcing (onshore, offshore, nearshore); dimensione dell'organizzazione (grandi imprese, PMI); settore dell'utente finale (BFSI, IT e telecomunicazioni, assistenza sanitaria, vendita al dettaglio ed e-commerce, produzione, altro); e regione/stati

Mercato della Tecnologia Gi-Fi: Analisi attuale e previsioni (2025-2033)
Enfasi su Tipo di Prodotto (Dispositivi di Visualizzazione e Dispositivi di Infrastruttura di Rete); Tecnologia (System on chip e Chip di Circuito Integrato); Applicazione (Elettronica di Consumo, Commerciale e Networking); e Regione/Paese

Mercato dell'archiviazione dati su DNA: analisi attuale e previsioni (2026-2034)
Enfasi su Tipologia (Cloud e On-Premise); Tecnologia (Archiviazione Dati DNA Basata su Sequenza e Archiviazione Dati DNA Basata su Struttura); Utente Finale (Governo, Sanità e Biotecnologie, Media e Telecomunicazioni e Altri); e Regione/Paese

Mercato del Cloud Service Brokerage: Analisi attuale e previsioni (2026-2034)
Focus sul tipo di servizio (Integrazione e supporto, Automazione e orchestrazione, Fatturazione e provisioning, Migrazione e personalizzazione, Sicurezza e conformità e Altri); Piattaforma (Abilitazione dell'intermediazione interna e Abilitazione dell'intermediazione esterna); Implementazione (Privata, Pubblica e Ibrida); Dimensione aziendale (Grandi imprese e Piccole e medie imprese); Uso finale (IT e telecomunicazioni, BFSI, Settore pubblico e governativo, Sanità, Beni di consumo e vendita al dettaglio, Produzione, Energia e servizi di pubblica utilità e Altri); e Regione/Paese

