سوق مجموعة بيانات تدريب الذكاء الاصطناعي: التحليل الحالي والتوقعات (2024-2032)
التركيز على النوع (نص، صوت، صورة، فيديو، وغيرها (أجهزة الاستشعار والجغرافيا))؛ وضع النشر (السحابة والحوسبة المحلية)؛ المستخدم النهائي (تكنولوجيا المعلومات والاتصالات، البيع بالتجزئة والسلع الاستهلاكية، الرعاية الصحية، السيارات، BFSI، وغيرها (الحكومة والتصنيع))؛ والمنطقة/البلد
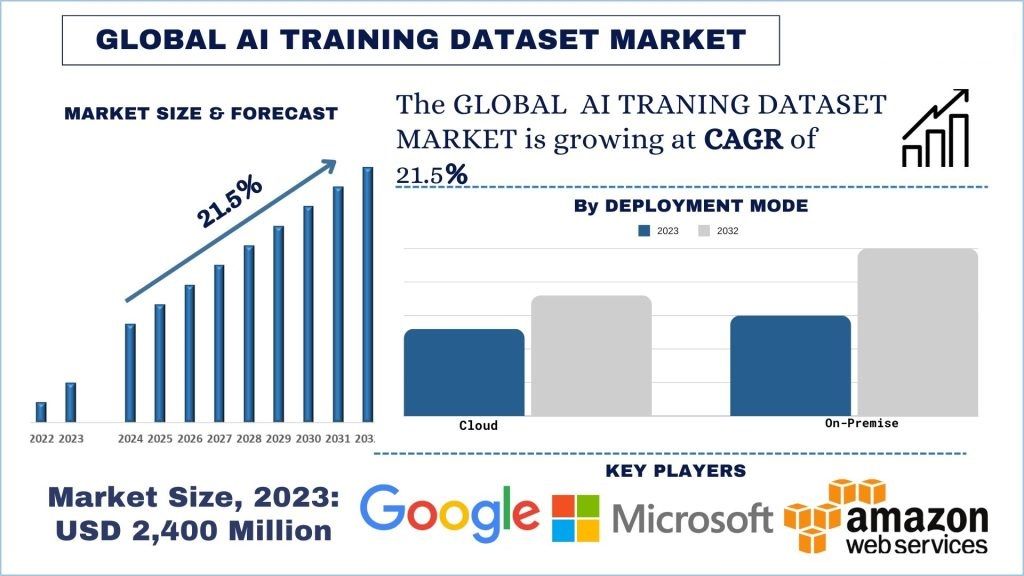
حجم سوق مجموعة بيانات التدريب الخاصة بالذكاء الاصطناعي والتوقعات
قُدرت قيمة سوق مجموعة بيانات التدريب الخاصة بالذكاء الاصطناعي بمبلغ 2,400 مليون دولار أمريكي ومن المتوقع أن ينمو بمعدل نمو سنوي مركب قوي يبلغ حوالي 21.5٪ خلال الفترة المتوقعة (2024-2032) نظرًا لتزايد انتشار تطوير ونشر تطبيقات الذكاء الاصطناعي والتعلم الآلي.
تحليل سوق مجموعة بيانات التدريب الخاصة بالذكاء الاصطناعي
تعد مجموعات بيانات التدريب الخاصة بالذكاء الاصطناعي هي البيانات الأساسية المستخدمة لتدريب وتطوير نماذج التعلم الآلي والذكاء الاصطناعي. تتكون هذه المجموعات من أمثلة مصنفة تستخدمها نماذج الذكاء الاصطناعي لتعلم الأنماط والعلاقات وإجراء تنبؤات دقيقة. يتم جمع مجموعات البيانات من مصادر مختلفة مثل قواعد البيانات والمواقع الإلكترونية والمقالات وتسجيلات الفيديو ووسائل التواصل الاجتماعي ومصادر البيانات الأخرى ذات الصلة. الهدف هو جمع مجموعة متنوعة وممثلة من البيانات. يتم تصنيف البيانات الأولية بعناية وشرحها لتزويد نموذج الذكاء الاصطناعي بمعلومات دقيقة يمكن التعلم منها. يتضمن ذلك تصنيف البيانات ووضع علامات عليها ووصفها.

شهد مجال الذكاء الاصطناعي (AI) نموًا وتقدمًا غير مسبوقين في السنوات الأخيرة، حيث أصبحت التطبيقات والتقنيات التي تعمل بالذكاء الاصطناعي منتشرة بشكل متزايد في مختلف الصناعات. أدى هذا التوسع السريع للذكاء الاصطناعي إلى زيادة مقابلة في الطلب على مجموعات بيانات التدريب الخاصة بالذكاء الاصطناعي عالية الجودة والمتنوعة والشاملة لتشغيل هذه الأنظمة المتقدمة. علاوة على ذلك، كان التبني المتزايد للتقنيات التي تعمل بالذكاء الاصطناعي في قطاعات مثل الرعاية الصحية والمالية والتجارة الإلكترونية والنقل محركًا رئيسيًا للطلب على مجموعات بيانات التدريب الخاصة بالذكاء الاصطناعي. بينما تسعى الشركات والمؤسسات إلى الاستفادة من قوة الذكاء الاصطناعي لتحسين عملياتها وتحسين اتخاذ القرارات وتقديم تجارب مخصصة، فقد ارتفعت الحاجة إلى مجموعات بيانات قوية وموثوقة ومتنوعة لتدريب نماذج الذكاء الاصطناعي هذه بشكل كبير. بالإضافة إلى ذلك، كان النمو في شعبية وانتشار التعلم الآلي (ML) وخوارزميات التعلم العميق (DL) عاملاً هامًا في زيادة الطلب على مجموعات بيانات التدريب الخاصة بالذكاء الاصطناعي. تعتمد هذه التقنيات المتقدمة على كميات هائلة من البيانات لتدريب نماذجها وتعلم الأنماط وإجراء تنبؤات دقيقة. على سبيل المثال، في كوريا الجنوبية، ظهرت بيانات العملاء كمصدر المعلومات الأساسي لتدريب نماذج الذكاء الاصطناعي (AI) في عام 2022، وفقًا لما ذكرته حوالي 70 بالمائة من الشركات التي شملها الاستطلاع. علاوة على ذلك، أشار ما يقرب من 62 بالمائة من المشاركين إلى استخدامهم للبيانات الداخلية لتدريب نماذج الذكاء الاصطناعي الخاصة بهم.
اتجاهات سوق مجموعة بيانات التدريب الخاصة بالذكاء الاصطناعي
يناقش هذا القسم اتجاهات السوق الرئيسية التي تؤثر على مختلف قطاعات سوق مجموعة بيانات التدريب الخاصة بالذكاء الاصطناعي، كما حددها فريق خبراء الأبحاث لدينا.
تُستخدم مجموعات بيانات التنسيق النصي في الغالب لتدريب نماذج الذكاء الاصطناعي والتعلم الآلي حاليًا وتُنشئ الجزء الأكبر من الإيرادات لصناعة مجموعة بيانات التدريب الخاصة بالذكاء الاصطناعي.
تنتشر البيانات النصية في العصر الرقمي، مع وجود كميات هائلة من المعلومات المتاحة على الإنترنت، وفي الكتب والمقالات ووسائل التواصل الاجتماعي ومصادر أخرى مختلفة. مجموعات البيانات النصية أسهل عمومًا في الجمع والتخزين والمعالجة مقارنة بأنواع البيانات الأخرى، مثل الصوت أو الفيديو. علاوة على ذلك، يمكن استخدام البيانات النصية لتدريب مجموعة واسعة من نماذج الذكاء الاصطناعي والتعلم الآلي، بما في ذلك نماذج معالجة اللغة الطبيعية (NLP) لمهام مثل تحليل المشاعر وتصنيف النصوص وتوليد اللغة والترجمة الآلية. يمكن أيضًا استخدام البيانات النصية لتدريب نماذج للمهام التي تتجاوز معالجة اللغة الطبيعية، مثل تلخيص المستندات واسترجاع المعلومات وحتى مهام تحليل الصور والفيديو. تتيح تعددية استخدامات البيانات النصية تطوير مجموعة متنوعة من تطبيقات الذكاء الاصطناعي والتعلم الآلي، من روبوتات المحادثة والمساعدين الافتراضيين إلى أنظمة توصية المحتوى وأدوات الكتابة الآلية. بالإضافة إلى ذلك، تكون معالجة البيانات النصية بشكل عام أقل كثافة من الناحية الحسابية مقارنة بأنواع البيانات الأخرى، مثل الصور أو مقاطع الفيديو عالية الدقة، التي تتطلب أجهزة أكثر قوة وموارد حسابية أكبر. هذا يجعل نماذج الذكاء الاصطناعي والتعلم الآلي القائمة على النصوص أكثر سهولة وجدوى للتطوير والنشر، خاصة على الأجهزة ذات الموارد المحدودة أو في السيناريوهات ذات القدرة الحسابية المحدودة. العوامل مثل هذه تعزز بيئة مواتية، مما يدفع إلى زيادة الطلب على مجموعات البيانات النصية لتدريب نماذج الذكاء الاصطناعي والتعلم الآلي المختلفة.
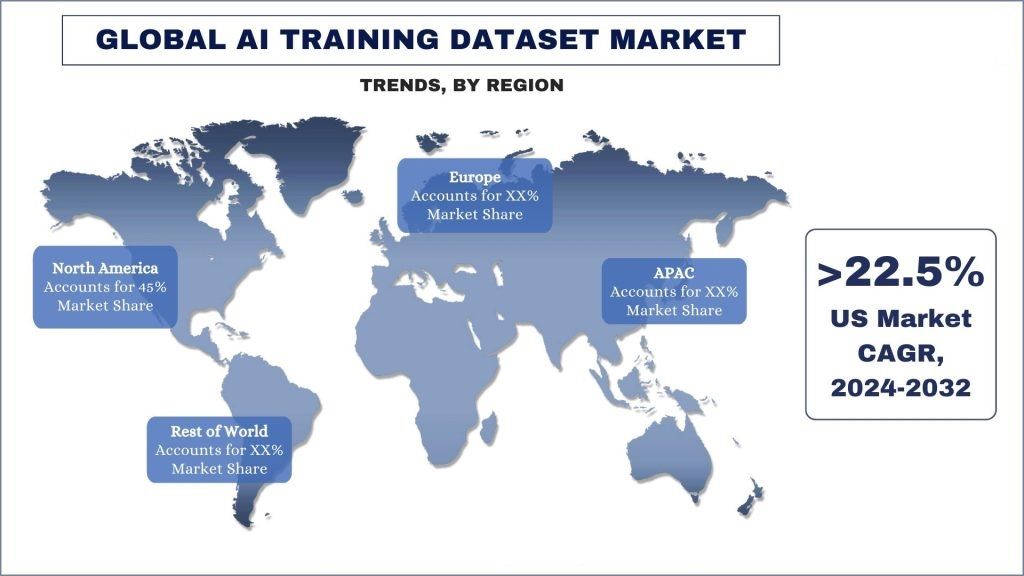
تظهر أمريكا الشمالية كأسرع الأسواق نموًا وتمثل جزءًا كبيرًا من سوق مجموعة بيانات التدريب الخاصة بالذكاء الاصطناعي على مستوى العالم.
ظهرت أمريكا الشمالية كواحدة من أكبر الأسواق وأسرعها نموًا لمجموعات بيانات التدريب الخاصة بالذكاء الاصطناعي. تعد الولايات المتحدة موطنًا لبعض من أبرز الجامعات البحثية في العالم، مثل ستانفورد ومعهد ماساتشوستس للتكنولوجيا وكارنيجي ميلون، والتي حققت خطوات كبيرة في أبحاث الذكاء الاصطناعي والتعلم الآلي. علاوة على ذلك، أنشأت شركات التكنولوجيا البارزة، بما في ذلك Google وMicrosoft وAmazon، مختبرات أبحاث الذكاء الاصطناعي المتطورة في أمريكا الشمالية، مما زاد من دفع الابتكار والتقدم في هذا المجال. بالإضافة إلى ذلك، أدركت الحكومة الأمريكية الأهمية الإستراتيجية للذكاء الاصطناعي واستثمرت بكثافة في دعم البحث والتطوير من خلال مبادرات مثل المبادرة الوطنية للذكاء الاصطناعي. علاوة على ذلك، تستثمر شركات التكنولوجيا الكبرى في أمريكا الشمالية بنشاط في تدريب واستبقاء أفضل المواهب في مجال الذكاء الاصطناعي والتعلم الآلي، مما يخلق دورة ذاتية التعزيز من الابتكار والنمو. أخيرًا، تعد أمريكا الشمالية، وخاصة الولايات المتحدة، موطنًا لنظام بيئي مزدهر لرأس المال الاستثماري الذي يصب مليارات الدولارات في الشركات الناشئة والشركات العاملة في مجال الذكاء الاصطناعي والتعلم الآلي. أدى وجود مراكز التكنولوجيا الكبرى، مثل Silicon Valley وبوسطن ونيويورك، إلى تسهيل تدفق رأس المال الاستثماري إلى صناعة الذكاء الاصطناعي والتعلم الآلي. على سبيل المثال، في عام 2023، وفقًا لبيانات S&P Global Market Intelligence، شهدت الاستثمارات في شركات الذكاء الاصطناعي التوليدية زيادة كبيرة، وتجاوزت الانخفاض في نشاط الاندماج والاستحواذ الإجمالي. استثمرت شركات الأسهم الخاصة 2.18 مليار دولار أمريكي في الذكاء الاصطناعي التوليدي، أي ضعف الإجمالي في العام السابق. حدثت هذه الزيادة في رأس المال وسط انخفاض في معاملات الاندماج والاستحواذ المدعومة بالأسهم الخاصة عبر الصناعات في عام 2023. جعلت عوامل مثل هذه أمريكا الشمالية قوة مهيمنة في صناعة الذكاء الاصطناعي والتعلم الآلي، مما أدى بالتالي إلى زيادة الطلب على خدمات مجموعة بيانات التدريب الخاصة بالذكاء الاصطناعي لدعم معدل النمو غير المسبوق لصناعة الذكاء الاصطناعي.
نظرة عامة على صناعة مجموعة بيانات التدريب الخاصة بالذكاء الاصطناعي
يتسم سوق مجموعة بيانات التدريب الخاصة بالذكاء الاصطناعي بالتنافسية والتشرذم، مع وجود العديد من اللاعبين العالميين والدوليين في السوق. يتبنى اللاعبون الرئيسيون استراتيجيات نمو مختلفة لتعزيز وجودهم في السوق، مثل الشراكات والاتفاقيات والتعاون وإطلاق المنتجات الجديدة والتوسعات الجغرافية وعمليات الاندماج والاستحواذ. بعض اللاعبين الرئيسيين العاملين في السوق هم Google وMicrosoft وAmazon Web Services, Inc. وIBM وOracle وAlegion AI, Inc. وTELUS International وLionbridge Technologies, LLC وSamasource Impact Sourcing, Inc. وAppen Limited.
أخبار سوق مجموعة بيانات التدريب الخاصة بالذكاء الاصطناعي
- كشفت IBM عن IBM Watsonx في مؤتمر Think السنوي الذي عقدته في 9 مايو 2023. ستحدث منصة الذكاء الاصطناعي والبيانات الرائدة هذه ثورة في كيفية استخدام المؤسسات للذكاء الاصطناعي المتقدم مع الحفاظ على موثوقية البيانات. من خلال IBM Watsonx، يمكن للمؤسسات الوصول إلى مجموعة شاملة من التقنيات لتدريب نماذج الذكاء الاصطناعي وضبطها ونشرها، بما في ذلك النماذج التأسيسية وقدرات التعلم الآلي. كما يتيح الاستخدام السلس للبيانات الموثوقة عبر بيئات سحابية مختلفة، مما يضمن السرعة والإدارة والتوافق.
- كشفت Baidu في أبريل 2024 عن مجموعة من أدوات الذكاء الاصطناعي الجديدة المصممة لتمكين الأفراد الذين ليس لديهم خبرة في البرمجة من تطوير روبوتات المحادثة التي تعتمد على الذكاء الاصطناعي التوليدي والمصممة خصيصًا لأغراض معينة. يمكن بعد ذلك دمج روبوتات المحادثة هذه في موقع ويب أو نتائج محرك بحث Baidu أو أي منصات أخرى عبر الإنترنت.
تغطية تقرير سوق مجموعة بيانات التدريب الخاصة بالذكاء الاصطناعي
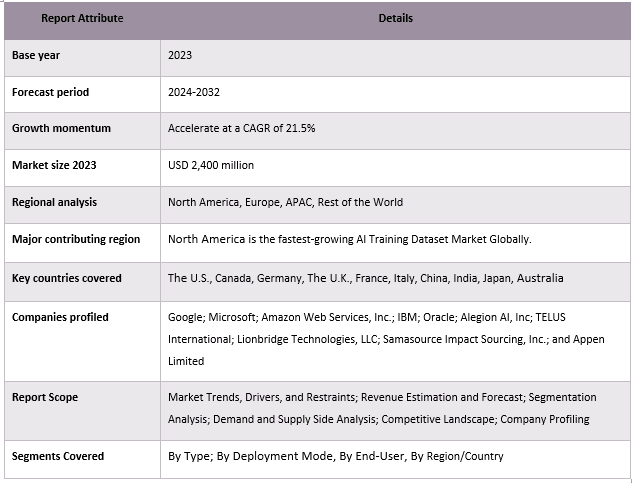
تغطية تقرير سوق مجموعة بيانات التدريب الخاصة بالذكاء الاصطناعي
أسباب شراء هذا التقرير:
- تتضمن الدراسة تحليل حجم السوق والتنبؤ به تم التحقق منه من قبل خبراء الصناعة الرئيسيين الموثوق بهم.
- يقدم التقرير مراجعة سريعة للأداء العام للصناعة في لمحة.
- يغطي التقرير تحليلًا متعمقًا لأقران الصناعة البارزين مع التركيز الأساسي على البيانات المالية التجارية الرئيسية ومحافظ المنتجات واستراتيجيات التوسع والتطورات الأخيرة.
- دراسة تفصيلية للمحركات والقيود والاتجاهات الرئيسية والفرص السائدة في الصناعة.
- تغطي الدراسة السوق بشكل شامل عبر قطاعات مختلفة.
- تحليل متعمق على المستوى الإقليمي للصناعة.
خيارات التخصيص:
يمكن تخصيص سوق مجموعة بيانات التدريب الخاصة بالذكاء الاصطناعي العالمية بشكل أكبر وفقًا للمتطلبات أو أي قطاع سوق آخر. إلى جانب ذلك، تتفهم UMI أنه قد تكون لديك احتياجات عمل خاصة بك؛ لذلك، لا تتردد في الاتصال بنا للحصول على تقرير يناسب متطلباتك تمامًا.
جدول المحتويات
منهجية البحث لتحليل سوق مجموعة بيانات التدريب على الذكاء الاصطناعي (2024-2032)
كان تحليل السوق التاريخي، وتقدير السوق الحالي، والتنبؤ بالسوق المستقبلي لسوق مجموعة بيانات التدريب على الذكاء الاصطناعي العالمي هي الخطوات الرئيسية الثلاث التي تم اتخاذها لإنشاء وتحليل اعتماد مجموعات بيانات التدريب على الذكاء الاصطناعي في المناطق الرئيسية على مستوى العالم. تم إجراء بحث ثانوي شامل لجمع أرقام السوق التاريخية وتقدير حجم السوق الحالي. ثانيًا، للتحقق من صحة هذه الرؤى، تم أخذ العديد من النتائج والافتراضات في الاعتبار. علاوة على ذلك، تم إجراء مقابلات أولية شاملة مع خبراء الصناعة عبر سلسلة القيمة لسوق مجموعة بيانات التدريب على الذكاء الاصطناعي العالمي. بعد افتراض أرقام السوق والتحقق من صحتها من خلال المقابلات الأولية؛ استخدمنا نهجًا من أعلى إلى أسفل/من أسفل إلى أعلى للتنبؤ بحجم السوق بالكامل. بعد ذلك، تم اعتماد أساليب تقسيم السوق وتثليث البيانات لتقدير وتحليل حجم سوق القطاعات والقطاعات الفرعية في الصناعة. تم شرح المنهجية التفصيلية أدناه:
تحليل حجم السوق التاريخي
الخطوة 1: دراسة متعمقة للمصادر الثانوية:
تم إجراء دراسة ثانوية مفصلة للحصول على حجم السوق التاريخي لسوق مجموعة بيانات التدريب على الذكاء الاصطناعي من خلال مصادر الشركة الداخلية مثل التقارير السنوية والبيانات المالية، وعروض الأداء، والنشرات الصحفية، وما إلى ذلك، والمصادر الخارجية بما في ذلك المجلات، والأخبار والمقالات، والمنشورات الحكومية، ومنشورات المنافسين، وتقارير القطاعات، وقاعدة بيانات الطرف الثالث، والمنشورات الموثوقة الأخرى.
الخطوة 2: تجزئة السوق:
بعد الحصول على حجم السوق التاريخي لسوق مجموعة بيانات التدريب على الذكاء الاصطناعي، أجرينا تحليلًا ثانويًا مفصلًا لجمع رؤى السوق التاريخية وحصصها للقطاعات والقطاعات الفرعية المختلفة للمناطق الرئيسية. يتم تضمين القطاعات الرئيسية في التقرير كنوع ونمط النشر والمستخدم النهائي. تم إجراء المزيد من التحليلات على مستوى الدولة لتقييم الاعتماد الكلي لنماذج الاختبار في تلك المنطقة.
الخطوة 3: تحليل العوامل:
بعد الحصول على حجم السوق التاريخي للقطاعات والقطاعات الفرعية المختلفة، أجرينا تحليلًا تفصيليًا للعوامل لتقدير حجم السوق الحالي لسوق مجموعة بيانات التدريب على الذكاء الاصطناعي. علاوة على ذلك، أجرينا تحليلًا للعوامل باستخدام متغيرات تابعة ومستقلة مثل النوع ونمط النشر والمستخدم النهائي لسوق مجموعة بيانات التدريب على الذكاء الاصطناعي. تم إجراء تحليل شامل لسيناريوهات الطلب والعرض مع الأخذ في الاعتبار أهم الشراكات وعمليات الاندماج والاستحواذ والتوسع التجاري وإطلاق المنتجات في قطاع سوق مجموعة بيانات التدريب على الذكاء الاصطناعي في جميع أنحاء العالم.
تقدير حجم السوق الحالي والتنبؤ به
تحديد حجم السوق الحالي: بناءً على رؤى قابلة للتنفيذ من الخطوات الثلاث المذكورة أعلاه، توصلنا إلى حجم السوق الحالي، واللاعبين الرئيسيين في سوق مجموعة بيانات التدريب على الذكاء الاصطناعي العالمي، والحصص السوقية للقطاعات. تم تحديد جميع الحصص المئوية المطلوبة وتقسيمات السوق باستخدام النهج الثانوي المذكور أعلاه وتم التحقق منها من خلال المقابلات الأولية.
التقدير والتنبؤ: لتقدير السوق والتنبؤ به، تم تخصيص أوزان لعوامل مختلفة بما في ذلك المحركات والاتجاهات والقيود والفرص المتاحة لأصحاب المصلحة. بعد تحليل هذه العوامل، تم تطبيق تقنيات التنبؤ ذات الصلة، أي النهج من أعلى إلى أسفل/من أسفل إلى أعلى، للتوصل إلى توقعات السوق لعام 2032 للقطاعات والقطاعات الفرعية المختلفة عبر الأسواق الرئيسية على مستوى العالم. تتضمن منهجية البحث المعتمدة لتقدير حجم السوق ما يلي:
- حجم سوق الصناعة، من حيث الإيرادات (بالدولار الأمريكي) ومعدل اعتماد سوق مجموعة بيانات التدريب على الذكاء الاصطناعي عبر الأسواق الرئيسية محليًا
- جميع الحصص المئوية والتقسيمات والتوزيعات لقطاعات السوق وقطاعاته الفرعية
- اللاعبون الرئيسيون في سوق مجموعة بيانات التدريب على الذكاء الاصطناعي العالمي من حيث المنتجات المعروضة. أيضًا، استراتيجيات النمو التي اعتمدها هؤلاء اللاعبون للمنافسة في السوق سريع النمو.
التحقق من صحة حجم السوق وحصته
البحث الأولي: تم إجراء مقابلات متعمقة مع قادة الرأي الرئيسيين (KOLs)، بمن فيهم كبار المسؤولين التنفيذيين (CXO/VPs، ورئيس المبيعات، ورئيس التسويق، والرئيس التشغيلي، والرئيس الإقليمي، ورئيس الدولة، وما إلى ذلك) عبر المناطق الرئيسية. ثم تم تلخيص نتائج البحث الأولي، وتم إجراء تحليل إحصائي لإثبات الفرضية المذكورة. تم دمج مدخلات البحث الأولي مع النتائج الثانوية، وبالتالي تحويل المعلومات إلى رؤى قابلة للتنفيذ.
تقسيم المشاركين الأساسيين في المناطق المختلفة
هندسة السوق
تم استخدام تقنية تثليث البيانات لإكمال تقدير السوق الإجمالي والتوصل إلى أرقام إحصائية دقيقة لكل قطاع وقطاع فرعي في سوق مجموعة بيانات التدريب على الذكاء الاصطناعي العالمي. تم تقسيم البيانات إلى عدة قطاعات وقطاعات فرعية بعد دراسة العديد من المعلمات والاتجاهات في مجالات النوع ونمط النشر والمستخدم النهائي في سوق مجموعة بيانات التدريب على الذكاء الاصطناعي العالمي.
الهدف الرئيسي لدراسة سوق مجموعة بيانات التدريب على الذكاء الاصطناعي العالمي
تم تحديد اتجاهات السوق الحالية والمستقبلية لسوق مجموعة بيانات التدريب على الذكاء الاصطناعي العالمي في الدراسة. يمكن للمستثمرين الحصول على رؤى استراتيجية لترسيخ تقديرهم للاستثمارات بناءً على التحليل النوعي والكمي الذي تم إجراؤه في الدراسة. حددت اتجاهات السوق الحالية والمستقبلية الجاذبية الإجمالية للسوق على المستوى الإقليمي، مما يوفر منصة للمشارك الصناعي لاستغلال السوق غير المستغل للاستفادة من ميزة الريادة. تشمل الأهداف الكمية الأخرى للدراسات ما يلي:
- تحليل حجم السوق الحالي والمتوقع لسوق مجموعة بيانات التدريب على الذكاء الاصطناعي من حيث القيمة (بالدولار الأمريكي). أيضًا، تحليل حجم السوق الحالي والمتوقع للقطاعات والقطاعات الفرعية المختلفة.
- تشمل القطاعات في الدراسة مجالات النوع ونمط النشر والمستخدم النهائي
- تحديد وتحليل الإطار التنظيمي لمجموعة بيانات التدريب على الذكاء الاصطناعي
- تحليل سلسلة القيمة المتضمنة مع وجود وسطاء مختلفين، جنبًا إلى جنب مع تحليل سلوكيات العملاء والمنافسين في الصناعة
- تحليل حجم السوق الحالي والمتوقع لسوق مجموعة بيانات التدريب على الذكاء الاصطناعي للمنطقة الرئيسية
- تشمل الدول الرئيسية في المناطق التي تمت دراستها في التقرير منطقة آسيا والمحيط الهادئ وأوروبا وأمريكا الشمالية وبقية دول العالم
- الملفات التعريفية للشركات لسوق مجموعة بيانات التدريب على الذكاء الاصطناعي واستراتيجيات النمو التي اعتمدها اللاعبون في السوق للحفاظ على استمرارهم في السوق سريع النمو.
- تحليل متعمق على المستوى الإقليمي للصناعة
الأسئلة الشائعة الأسئلة الشائعة
س1: ما هو حجم السوق الحالي وإمكانات النمو لسوق مجموعة بيانات تدريب الذكاء الاصطناعي العالمي؟
س٢: ما هي العوامل الدافعة لنمو سوق مجموعة بيانات التدريب على الذكاء الاصطناعي العالمي؟
س3: أي شريحة تستحوذ على الجزء الأكبر من السوق العالمي لمجموعة بيانات تدريب الذكاء الاصطناعي حسب المستخدم النهائي؟
س4: ما هي التقنيات والاتجاهات الناشئة في سوق مجموعة بيانات تدريب الذكاء الاصطناعي العالمي؟
س5: أي منطقة ستكون الأسرع نموًا في سوق مجموعة بيانات تدريب الذكاء الاصطناعي العالمي؟
س6: من هم اللاعبون الرئيسيون في سوق مجموعة بيانات تدريب الذكاء الاصطناعي العالمي؟
ذات صلة التقارير
العملاء الذين اشتروا هذا المنتج اشتروا أيضًا





سوق خدمات تكنولوجيا المعلومات وخدمات دعم الأعمال في الهند: تحليل حالي وتوقعات (2026-2034)
التركيز على نوع الخدمة (خدمات تكنولوجيا المعلومات، خدمات دعم الأعمال، خدمات الهندسة والبحث والتطوير)؛ نوع الاستعانة بمصادر خارجية (محلية، خارجية، قريبة)؛ حجم المؤسسة (المؤسسات الكبيرة، الشركات الصغيرة والمتوسطة)؛ صناعة المستخدم النهائي (الخدمات المصرفية والمالية والتأمين وتكنولوجيا المعلومات والاتصالات، الرعاية الصحية، البيع بالتجزئة والتجارة الإلكترونية، التصنيع، أخرى)؛ والمنطقة/الولايات

سوق تكنولوجيا Gi-Fi: التحليل الحالي والتوقعات (2025-2033)
التركيز على نوع المنتج (أجهزة العرض وأجهزة البنية التحتية للشبكات)؛ التكنولوجيا (نظام على شريحة وشريحة الدوائر المتكاملة)؛ التطبيق (الإلكترونيات الاستهلاكية والتجارية والشبكات)؛ والمنطقة/الدولة

سوق تخزين بيانات الحمض النووي: التحليل الحالي والتوقعات (2026-2034)
التركيز على النوع (السحابة والمحلية)؛ التكنولوجيا (تخزين بيانات الحمض النووي القائم على التسلسل وتخزين بيانات الحمض النووي القائم على الهيكل)؛ المستخدم النهائي (الحكومة، الرعاية الصحية والتكنولوجيا الحيوية، الإعلام والاتصالات، وغيرها)؛ والمنطقة/الدولة

سوق وساطة الخدمات السحابية: التحليل الحالي والتوقعات (2026-2034)
التركيز على نوع الخدمة (التكامل والدعم، والأتمتة والتنسيق، والفوترة والتزويد، والترحيل والتخصيص، والأمن والامتثال، وغيرها)؛ النظام الأساسي (تمكين الوساطة الداخلية وتمكين الوساطة الخارجية)؛ النشر (خاص، وعام، ومختلط)؛ حجم المؤسسة (المؤسسات الكبيرة، والمؤسسات الصغيرة والمتوسطة)؛ الاستخدام النهائي (تكنولوجيا المعلومات والاتصالات، والخدمات المصرفية والمالية والتأمين (BFSI)، والحكومة والقطاع العام، والرعاية الصحية، والسلع الاستهلاكية والتجزئة، والتصنيع، والطاقة والمرافق، وغيرها)؛ والمنطقة/الدولة

