KI-Trainingsdatensatzmarkt: Aktuelle Analyse und Prognose (2024-2032)
Schwerpunkt auf Typ (Text, Audio, Bild, Video und Sonstige (Sensor und Geo)); Bereitstellungsmodus (Cloud und On-Premise); Endbenutzer (IT und Telekommunikation, Einzelhandel und Konsumgüter, Gesundheitswesen, Automobil, BFSI und Sonstige (Regierung und Fertigung)); und Region/Land
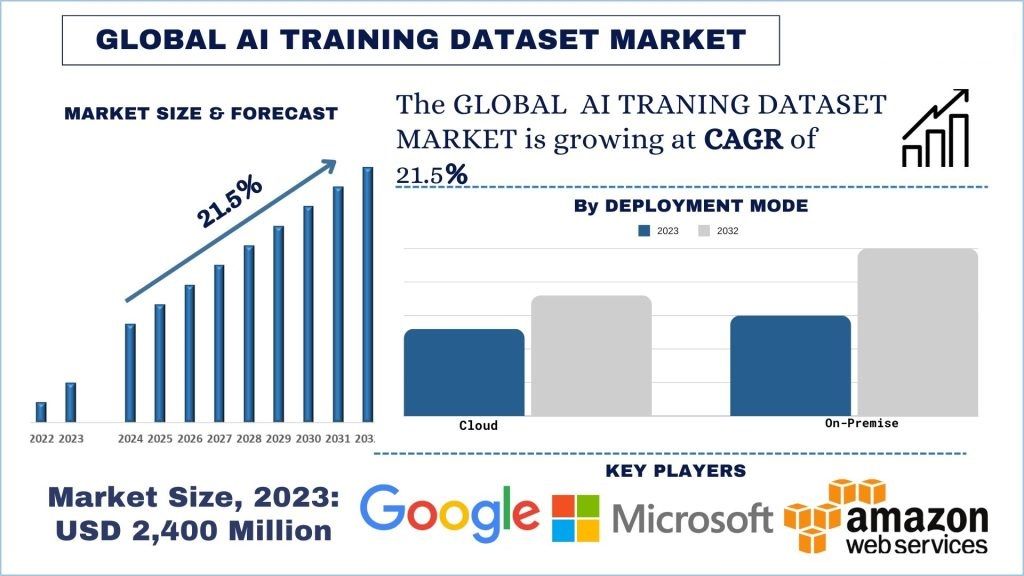
Marktgröße und Prognose für KI-Trainingsdatensätze
Der Markt für KI-Trainingsdatensätze wurde auf 2.400 Millionen USD geschätzt und wird voraussichtlich im Prognosezeitraum (2024-2032) mit einer starken CAGR von rund 21,5 % wachsen, was auf die zunehmende Verbreitung der Entwicklung und Bereitstellung von KI- und ML-Anwendungen zurückzuführen ist.
Marktanalyse für KI-Trainingsdatensätze
KI-Trainingsdatensätze sind die grundlegenden Daten, die zum Trainieren und Entwickeln von Modellen für maschinelles Lernen und künstliche Intelligenz verwendet werden. Diese Datensätze bestehen aus beschrifteten Beispielen, die die KI-Modelle verwenden, um Muster und Beziehungen zu erlernen und genaue Vorhersagen zu treffen. Datensätze werden aus verschiedenen Quellen wie Datenbanken, Websites, Artikeln, Videotranskripten, sozialen Medien und anderen relevanten Datenquellen gesammelt. Ziel ist es, einen vielfältigen und repräsentativen Datensatz zu sammeln. Die Rohdaten werden sorgfältig beschriftet und annotiert, um dem KI-Modell genaue Informationen zu liefern, aus denen es lernen kann. Dies beinhaltet die Kategorisierung, das Tagging und die Beschreibung der Daten.

Der Bereich der künstlichen Intelligenz (KI) hat in den letzten Jahren ein beispielloses Wachstum und Fortschritte erlebt, wobei KI-gestützte Anwendungen und Technologien in verschiedenen Branchen immer häufiger eingesetzt werden. Diese rasche Expansion der KI hat zu einem entsprechenden Anstieg der Nachfrage nach hochwertigen, vielfältigen und umfassenden KI-Trainingsdatensätzen geführt, um diese fortschrittlichen Systeme zu unterstützen. Darüber hinaus war die zunehmende Einführung KI-gestützter Technologien in Sektoren wie dem Gesundheitswesen, dem Finanzwesen, dem E-Commerce und dem Transportwesen ein wesentlicher Treiber für die Nachfrage nach KI-Trainingsdatensätzen. Da Unternehmen und Organisationen versuchen, die Leistungsfähigkeit der KI zu nutzen, um ihre Abläufe zu verbessern, die Entscheidungsfindung zu verbessern und personalisierte Erlebnisse zu bieten, ist der Bedarf an robusten, zuverlässigen und vielfältigen Datensätzen zum Trainieren dieser KI-Modelle sprunghaft angestiegen. Darüber hinaus war die wachsende Popularität und die breite Akzeptanz von Algorithmen für maschinelles Lernen (ML) und Deep Learning (DL) ein wesentlicher Faktor für den Anstieg der Nachfrage nach KI-Trainingsdatensätzen. Diese fortschrittlichen Techniken sind auf riesige Datenmengen angewiesen, um ihre Modelle zu trainieren, Muster zu erlernen und genaue Vorhersagen zu treffen. Beispielsweise stellten Kundendaten in Südkorea im Jahr 2022 die primäre Informationsquelle für das Training von Modellen der künstlichen Intelligenz (KI) dar, wie fast 70 Prozent der befragten Unternehmen angaben. Darüber hinaus gaben etwa 62 Prozent der Befragten an, interne Daten für das Training ihrer KI-Modelle zu verwenden.
Trends auf dem Markt für KI-Trainingsdatensätze
In diesem Abschnitt werden die wichtigsten Markttrends erörtert, die die verschiedenen Segmente des Marktes für KI-Trainingsdatensätze beeinflussen, wie sie von unserem Team von Forschungsexperten ermittelt wurden.
Die Textformat-Datensätze werden derzeit überwiegend für das Training von KI- und ML-Modellen verwendet und generieren den größten Teil des Umsatzes für die KI-Trainingsdatensatzindustrie.
Textdaten sind im digitalen Zeitalter allgegenwärtig, mit riesigen Mengen an Informationen, die im Internet, in Büchern, Artikeln, sozialen Medien und verschiedenen anderen Quellen verfügbar sind. Textdatensätze sind im Allgemeinen einfacher zu sammeln, zu speichern und zu verarbeiten als andere Datentypen wie Audio oder Video. Darüber hinaus können Textdaten verwendet werden, um eine breite Palette von KI- und ML-Modellen zu trainieren, darunter Modelle für die Verarbeitung natürlicher Sprache (NLP) für Aufgaben wie Sentimentanalyse, Textklassifizierung, Sprachgenerierung und maschinelle Übersetzung. Textdaten können auch verwendet werden, um Modelle für Aufgaben außerhalb der NLP zu trainieren, wie z. B. Dokumentzusammenfassung, Informationsabruf und sogar Bild- und Videoanalyseaufgaben. Die Vielseitigkeit von Textdaten ermöglicht die Entwicklung einer vielfältigen Palette von KI- und ML-Anwendungen, von Chatbots und virtuellen Assistenten bis hin zu Content-Empfehlungssystemen und automatisierten Schreibwerkzeugen. Darüber hinaus ist die Verarbeitung von Textdaten im Allgemeinen weniger rechenintensiv als die Verarbeitung anderer Datentypen wie hochauflösende Bilder oder Videos, die leistungsstärkere Hardware und größere Rechenressourcen erfordern. Dies macht textbasierte KI- und ML-Modelle zugänglicher und realisierbarer für die Entwicklung und Bereitstellung, insbesondere auf ressourcenbeschränkten Geräten oder in Szenarien mit begrenzter Rechenleistung. Faktoren wie diese fördern ein günstiges Umfeld und treiben den Anstieg der Nachfrage nach Textdatensätzen für das Training verschiedener KI- und ML-Modelle voran.
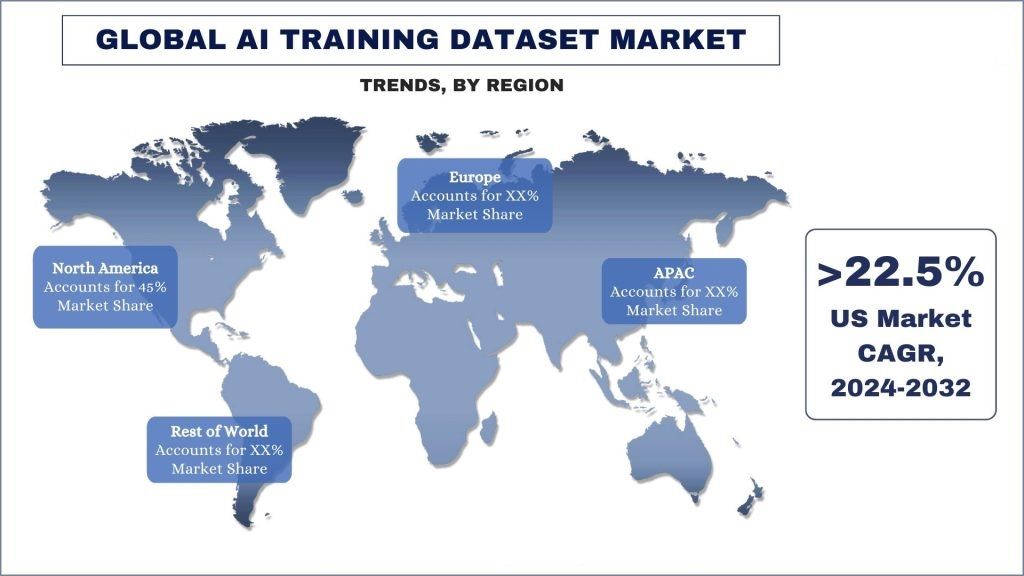
Nordamerika entwickelt sich zum am schnellsten wachsenden Markt und macht einen Großteil des Marktes für KI-Trainingsdatensätze weltweit aus.
Nordamerika hat sich zu einem der größten und am schnellsten wachsenden Märkte für KI-Trainingsdatensätze entwickelt. Die Vereinigten Staaten beherbergen einige der weltweit führenden Forschungsuniversitäten wie Stanford, MIT und Carnegie Mellon, die bedeutende Fortschritte in der KI- und ML-Forschung erzielt haben. Darüber hinaus haben prominente Technologieunternehmen wie Google, Microsoft und Amazon hochmoderne KI-Forschungslabore in Nordamerika eingerichtet, die Innovationen und Fortschritte in diesem Bereich weiter vorantreiben. Darüber hinaus hat die US-Regierung die strategische Bedeutung der KI erkannt und stark in die Unterstützung von Forschung und Entwicklung durch Initiativen wie die National Artificial Intelligence Initiative investiert. Darüber hinaus haben große Technologieunternehmen in Nordamerika aktiv in die Ausbildung und Bindung von Top-KI- und ML-Talenten investiert, wodurch ein sich selbst verstärkender Kreislauf von Innovation und Wachstum entsteht. Schließlich beherbergt Nordamerika, insbesondere die USA, ein florierendes Risikokapitalökosystem, das Milliarden von Dollar in KI- und ML-Startups und -Unternehmen investiert. Das Vorhandensein großer Technologiezentren wie Silicon Valley, Boston und New York hat den Fluss von Investitionskapital in die KI- und ML-Industrie erleichtert. So stiegen die Investitionen in generative KI-Unternehmen im Jahr 2023 laut den Daten von S&P Global Market Intelligence deutlich an und übertrafen den Rückgang der gesamten M&A-Aktivitäten. Private-Equity-Firmen investierten 2,18 Milliarden US-Dollar in generative KI, was einer Verdoppelung des Vorjahresbetrags entspricht. Dieser Kapitalanstieg erfolgte inmitten eines Rückgangs der durch Private Equity unterstützten M&A-Transaktionen in allen Branchen im Jahr 2023. Faktoren wie diese haben Nordamerika zu einer vorherrschenden Kraft in der KI- und ML-Industrie gemacht, was folglich die Nachfrage nach KI-Trainingsdatensatzdiensten angekurbelt hat, um diese beispiellose Wachstumsrate der KI-Industrie zu unterstützen.
Überblick über die KI-Trainingsdatensatzindustrie
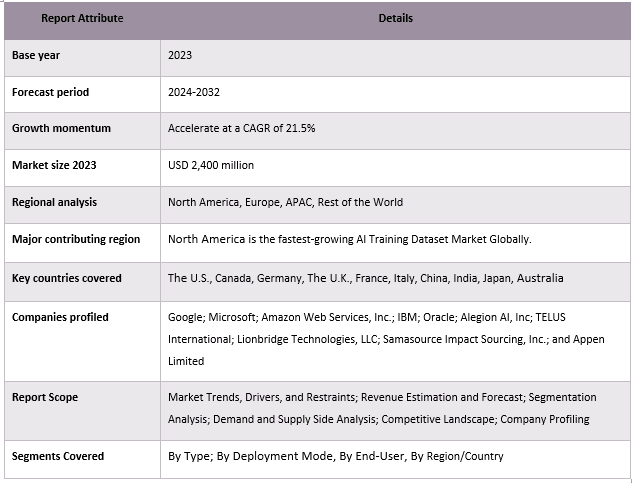
Der Markt für KI-Trainingsdatensätze ist wettbewerbsintensiv und fragmentiert, mit der Präsenz mehrerer globaler und internationaler Marktteilnehmer. Die wichtigsten Akteure verfolgen unterschiedliche Wachstumsstrategien, um ihre Marktpräsenz zu verbessern, wie z. B. Partnerschaften, Vereinbarungen, Kooperationen, neue Produkteinführungen, geografische Expansionen sowie Fusionen und Übernahmen. Einige der wichtigsten Akteure, die auf dem Markt tätig sind, sind Google, Microsoft, Amazon Web Services, Inc., IBM, Oracle, Alegion AI, Inc., TELUS International, Lionbridge Technologies, LLC, Samasource Impact Sourcing, Inc. und Appen Limited.
Nachrichten zum Markt für KI-Trainingsdatensätze
- IBM stellte IBM Watsonx auf seiner jährlichen Think-Konferenz am 9. Mai 2023 vor. Diese bahnbrechende KI- und Datenplattform wird die Art und Weise revolutionieren, wie Unternehmen fortschrittliche KI nutzen und gleichzeitig die Datensicherheit gewährleisten. Mit IBM Watsonx können Unternehmen auf einen umfassenden Technologiestack für das Training, die Feinabstimmung und die Bereitstellung von KI-Modellen zugreifen, einschließlich grundlegender Modelle und Funktionen für maschinelles Lernen. Es ermöglicht auch die nahtlose Nutzung vertrauenswürdiger Daten in verschiedenen Cloud-Umgebungen, wodurch Geschwindigkeit, Governance und Kompatibilität gewährleistet werden.
- Baidu stellte im April 2024 eine Reihe neuer KI-Tools vor, die es Personen ohne Programmierkenntnisse ermöglichen sollen, generative KI-gesteuerte Chatbots zu entwickeln, die auf bestimmte Zwecke zugeschnitten sind. Diese Chatbots können anschließend in eine Website, die Ergebnisse der Baidu-Suchmaschine oder andere Online-Plattformen integriert werden.
Berichterstattung über den Marktbericht für KI-Trainingsdatensätze
Berichterstattung über den Marktbericht für KI-Trainingsdatensätze
Gründe für den Kauf dieses Berichts:
- Die Studie umfasst eine Analyse der Marktgröße und -prognose, die von authentifizierten wichtigen Branchenexperten validiert wurde.
- Der Bericht bietet einen schnellen Überblick über die Gesamtleistung der Branche auf einen Blick.
- Der Bericht umfasst eine eingehende Analyse prominenter Branchenkollegen mit einem primären Fokus auf wichtige Finanzdaten des Unternehmens, Produktportfolios, Expansionsstrategien und aktuelle Entwicklungen.
- Detaillierte Untersuchung von Treibern, Einschränkungen, wichtigen Trends und Chancen in der Branche.
- Die Studie deckt den Markt umfassend in verschiedenen Segmenten ab.
- Tiefgehende regionale Analyse der Branche.
Anpassungsoptionen:
Der globale Markt für KI-Trainingsdatensätze kann je nach Anforderung oder anderem Marktsegment weiter angepasst werden. Darüber hinaus versteht UMI, dass Sie möglicherweise Ihre eigenen geschäftlichen Anforderungen haben. Zögern Sie daher nicht, uns zu kontaktieren, um einen Bericht zu erhalten, der Ihren Anforderungen vollständig entspricht.
Inhaltsverzeichnis
Forschungsmethodik für die Marktanalyse des KI-Trainingsdatensatzes (2024-2032)
Die Analyse des historischen Marktes, die Schätzung des aktuellen Marktes und die Prognose des zukünftigen Marktes des globalen KI-Trainingsdatensatzmarktes waren die drei wichtigsten Schritte, die unternommen wurden, um die Einführung von KI-Trainingsdatensätzen in wichtigen Regionen weltweit zu erstellen und zu analysieren. Umfassende Sekundärforschung wurde durchgeführt, um die historischen Marktzahlen zu sammeln und die aktuelle Marktgröße zu schätzen. Zweitens wurden zahlreiche Erkenntnisse und Annahmen berücksichtigt, um diese Erkenntnisse zu validieren. Darüber hinaus wurden umfassende Primärinterviews mit Branchenexperten entlang der Wertschöpfungskette des globalen KI-Trainingsdatensatzmarktes geführt. Nach der Annahme und Validierung der Marktzahlen durch Primärinterviews wendeten wir einen Top-Down/Bottom-Up-Ansatz an, um die vollständige Marktgröße zu prognostizieren. Danach wurden Methoden zur Marktaufteilung und Datentriangulation angewendet, um die Marktgröße von Segmenten und Untersegmenten der Branche zu schätzen und zu analysieren. Die detaillierte Methodik wird im Folgenden erläutert:
Analyse der historischen Marktgröße
Schritt 1: Eingehende Untersuchung von Sekundärquellen:
Es wurde eine detaillierte Sekundärstudie durchgeführt, um die historische Marktgröße des KI-Trainingsdatensatzmarktes aus unternehmensinternen Quellen wie Jahresberichten und Finanzberichten, Performance-Präsentationen, Pressemitteilungen usw. und externen Quellen wie Fachzeitschriften, Nachrichten und Artikeln, Regierungsveröffentlichungen, Wettbewerbsveröffentlichungen, Sektorberichten, Datenbanken von Drittanbietern und anderen glaubwürdigen Veröffentlichungen zu erhalten.
Schritt 2: Marktsegmentierung:
Nachdem wir die historische Marktgröße des KI-Trainingsdatensatzmarktes ermittelt hatten, führten wir eine detaillierte Sekundäranalyse durch, um historische Markteinblicke und Anteile für verschiedene Segmente und Untersegmente für wichtige Regionen zu sammeln. Wichtige Segmente, die in dem Bericht enthalten sind, sind Typ, Bereitstellungsmodus und Endbenutzer. Darüber hinaus wurden Länderanalysen durchgeführt, um die allgemeine Einführung von Testmodellen in dieser Region zu bewerten.
Schritt 3: Faktorenanalyse:
Nachdem wir die historische Marktgröße verschiedener Segmente und Untersegmente ermittelt hatten, führten wir eine detaillierte Faktorenanalyse durch, um die aktuelle Marktgröße des KI-Trainingsdatensatzmarktes zu schätzen. Darüber hinaus führten wir eine Faktorenanalyse unter Verwendung von abhängigen und unabhängigen Variablen wie Typ, Bereitstellungsmodus und Endbenutzer des KI-Trainingsdatensatzmarktes durch. Es wurde eine gründliche Analyse von Angebots- und Nachfrageszenarien unter Berücksichtigung von Top-Partnerschaften, Fusionen und Übernahmen, Geschäftsausweitungen und Produkteinführungen im KI-Trainingsdatensatzmarktsektor auf der ganzen Welt durchgeführt.
Aktuelle Marktgrößenschätzung & Prognose
Aktuelle Marktgrößenbestimmung: Basierend auf den verwertbaren Erkenntnissen aus den oben genannten 3 Schritten ermittelten wir die aktuelle Marktgröße, die wichtigsten Akteure auf dem globalen KI-Trainingsdatensatzmarkt und die Marktanteile der Segmente. Alle erforderlichen prozentualen Anteile, Aufteilungen und Marktaufschlüsselungen wurden anhand des oben genannten sekundären Ansatzes ermittelt und durch Primärinterviews verifiziert.
Schätzung & Prognose: Für die Marktschätzung und -prognose wurden verschiedenen Faktoren Gewichte zugewiesen, darunter Treiber und Trends, Beschränkungen und Chancen, die den Stakeholdern zur Verfügung stehen. Nach der Analyse dieser Faktoren wurden relevante Prognosetechniken, d. h. der Top-Down/Bottom-Up-Ansatz, angewendet, um die Marktprognose für 2032 für verschiedene Segmente und Untersegmente in den wichtigsten Märkten weltweit zu erstellen. Die Forschungsmethodik zur Schätzung der Marktgröße umfasst:
- Die Marktgröße der Branche in Bezug auf Umsatz (USD) und die Akzeptanzrate des KI-Trainingsdatensatzmarktes in den wichtigsten Märkten im Inland
- Alle prozentualen Anteile, Aufteilungen und Aufschlüsselungen von Marktsegmenten und Untersegmenten
- Wichtige Akteure auf dem globalen KI-Trainingsdatensatzmarkt in Bezug auf die angebotenen Produkte. Auch die Wachstumsstrategien, die diese Akteure anwenden, um in dem schnell wachsenden Markt zu konkurrieren.
Validierung von Marktgröße und -anteil
Primärforschung: Es wurden eingehende Interviews mit den wichtigsten Meinungsführern (Key Opinion Leaders, KOLs) geführt, darunter Führungskräfte der obersten Ebene (CXO/VPs, Vertriebsleiter, Marketingleiter, Betriebsleiter, Regionalleiter, Länderleiter usw.) in den wichtigsten Regionen. Die Ergebnisse der Primärforschung wurden dann zusammengefasst und eine statistische Analyse durchgeführt, um die aufgestellte Hypothese zu beweisen. Die Erkenntnisse aus der Primärforschung wurden mit den Sekundärergebnissen zusammengeführt, wodurch Informationen in verwertbare Erkenntnisse umgewandelt wurden.
Aufteilung der Hauptteilnehmer in verschiedenen Regionen
Markt Engineering
Die Datentriangulationstechnik wurde eingesetzt, um die Gesamtmarktschätzung abzuschließen und genaue statistische Zahlen für jedes Segment und Untersegment des globalen KI-Trainingsdatensatzmarktes zu erhalten. Die Daten wurden in mehrere Segmente und Untersegmente aufgeteilt, nachdem verschiedene Parameter und Trends in den Bereichen Typ, Bereitstellungsmodus und Endbenutzer auf dem globalen KI-Trainingsdatensatzmarkt untersucht wurden.
Das Hauptziel der globalen KI-Trainingsdatensatzmarktstudie
Die aktuellen und zukünftigen Markttrends des globalen KI-Trainingsdatensatzmarktes wurden in der Studie genau bestimmt. Investoren können strategische Einblicke gewinnen, um ihre Entscheidungen für Investitionen auf der Grundlage der in der Studie durchgeführten qualitativen und quantitativen Analyse zu treffen. Aktuelle und zukünftige Markttrends bestimmten die Gesamtattraktivität des Marktes auf regionaler Ebene und boten den Industrieteilnehmern eine Plattform, um den unerschlossenen Markt zu nutzen und von einem First-Mover-Vorteil zu profitieren. Weitere quantitative Ziele der Studien sind:
- Analysieren Sie die aktuelle und prognostizierte Marktgröße des KI-Trainingsdatensatzmarktes in Bezug auf den Wert (USD). Analysieren Sie auch die aktuelle und prognostizierte Marktgröße verschiedener Segmente und Untersegmente.
- Segmente in der Studie umfassen die Bereiche Typ, Bereitstellungsmodus und Endbenutzer
- Definieren und analysieren Sie den regulatorischen Rahmen für den KI-Trainingsdatensatz
- Analysieren Sie die Wertschöpfungskette unter Beteiligung verschiedener Vermittler sowie die Analyse des Kunden- und Wettbewerberverhaltens der Branche
- Analysieren Sie die aktuelle und prognostizierte Marktgröße des KI-Trainingsdatensatzmarktes für die Hauptregion
- Zu den wichtigsten Ländern der in dem Bericht untersuchten Regionen gehören der asiatisch-pazifische Raum, Europa, Nordamerika und der Rest der Welt.
- Unternehmensprofile des KI-Trainingsdatensatzmarktes und die Wachstumsstrategien, die von den Marktakteuren angewendet werden, um sich in dem schnell wachsenden Markt zu behaupten.
- Detaillierte Analyse der Branche auf regionaler Ebene
Häufig gestellte Fragen FAQs
F1: Wie groß ist der aktuelle Markt und welches Wachstumspotenzial hat der globale Markt für KI-Trainingsdatensätze?
F2: Was sind die treibenden Faktoren für das Wachstum des globalen AI Training Dataset Marktes?
F3: Welches Segment hält den größten Anteil am globalen Markt für KI-Trainingsdatensätze nach Endverbraucher?
F4: Was sind die aufkommenden Technologien und Trends auf dem globalen Markt für KI-Trainingsdatensätze?
F5: Welche Region wird der am schnellsten wachsende globale KI-Trainingsdatensatz-Markt sein?
F6: Wer sind die Hauptakteure auf dem globalen Markt für KI-Trainingsdatensätze?
Verwandt Berichte
Kunden, die diesen Artikel gekauft haben, kauften auch





Indischer IT- und BPO-Services-Markt: Aktuelle Analyse und Prognose (2026-2034)
Schwerpunkt auf Dienstleistungstyp (IT-Dienstleistungen, BPO-Dienstleistungen, Engineering & F&E-Dienstleistungen); Outsourcing-Typ (Onshore, Offshore, Nearshore); Unternehmensgröße (Großunternehmen, KMUs); Endbenutzerbranche (BFSI, IT & Telekommunikation, Gesundheitswesen, Einzelhandel & E-Commerce, Fertigung, Sonstige); und Region/Bundesstaaten

Gi-Fi-Technologiemarkt: Aktuelle Analyse und Prognose (2025-2033)
Schwerpunkt auf Produkttyp (Anzeigegeräte und Netzwerk-Infrastrukturgeräte); Technologie (System-on-Chip und Integrierter Schaltkreis-Chip); Anwendung (Unterhaltungselektronik, Gewerbe und Vernetzung); und Region/Land

DNA-Datenspeichermarkt: Aktuelle Analyse und Prognose (2026-2034)
Schwerpunkt auf Typ (Cloud und On-Premises); Technologie (Sequenzbasierte DNA-Datenspeicherung und Strukturbasierte DNA-Datenspeicherung); Endverbraucher (Regierung, Gesundheitswesen & Biotechnologie, Medien & Telekommunikation und Sonstige); und Region/Land

Cloud Service Brokerage Markt: Aktuelle Analyse und Prognose (2026-2034)
Schwerpunkt auf Servicetyp (Integration und Support, Automatisierung und Orchestrierung, Abrechnung und Bereitstellung, Migration und Anpassung, Sicherheit und Compliance und Sonstige); Plattform (Interne Brokerage-Aktivierung und Externe Brokerage-Aktivierung); Bereitstellung (Privat, Öffentlich und Hybrid); Unternehmensgröße (Großunternehmen und Kleine & Mittelständische Unternehmen); Endverwendung (IT & Telekommunikation, BFSI, Regierung & Öffentlicher Sektor, Gesundheitswesen, Konsumgüter & Einzelhandel, Fertigung, Energie & Versorgung und Sonstige); und Region/Land

