Marché des ensembles de données d'entraînement pour l'IA : Analyse actuelle et prévisions (2024-2032)
Accent mis sur le type (texte, audio, image, vidéo et autres (capteur et géo)) ; mode de déploiement (cloud et sur site) ; utilisateur final (informatique et télécommunications, vente au détail et biens de consommation, santé, automobile, BFSI et autres (secteur public et fabrication)) ; et région/pays
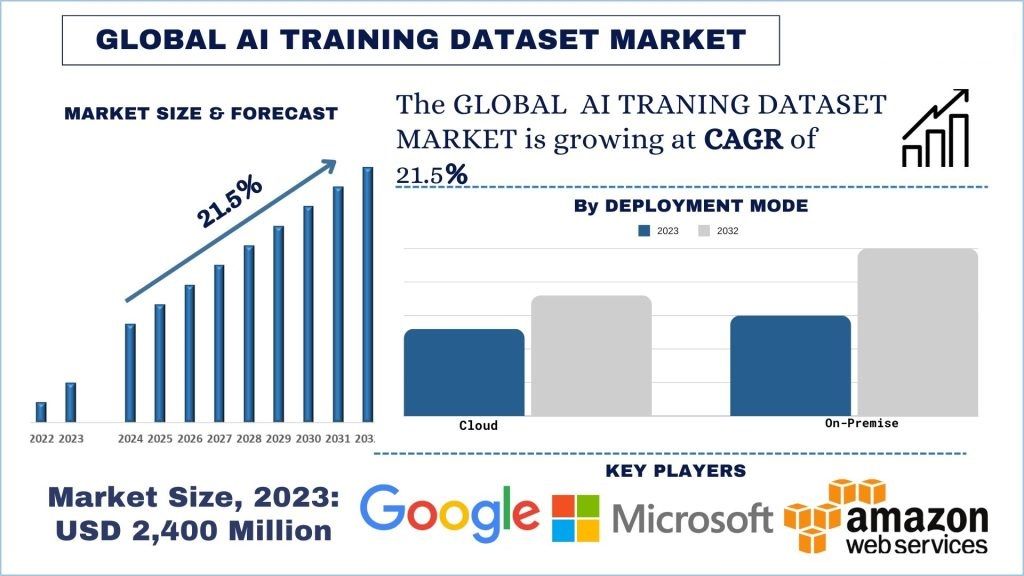
Taille et prévisions du marché des ensembles de données d'entraînement à l'IA
Le marché des ensembles de données d'entraînement à l'IA était évalué à 2 400 millions de dollars US et devrait croître à un TCAC important d'environ 21,5 % au cours de la période de prévision (2024-2032) en raison de la prolifération croissante du développement et du déploiement d'applications d'IA et d'apprentissage automatique.
Analyse du marché des ensembles de données d'entraînement à l'IA
Les ensembles de données d'entraînement à l'IA sont les données fondamentales utilisées pour entraîner et développer des modèles d'apprentissage automatique et d'intelligence artificielle. Ces ensembles de données sont constitués d'exemples étiquetés que les modèles d'IA utilisent pour apprendre des schémas et des relations et faire des prédictions précises. Les ensembles de données sont collectés à partir de diverses sources telles que des bases de données, des sites Web, des articles, des transcriptions vidéo, les médias sociaux et d'autres sources de données pertinentes. L'objectif est de rassembler un ensemble de données diversifié et représentatif. Les données brutes sont soigneusement étiquetées et annotées afin de fournir au modèle d'IA des informations précises à partir desquelles apprendre. Cela implique de catégoriser, d'étiqueter et de décrire les données.

Le domaine de l'intelligence artificielle (IA) a connu une croissance et des progrès sans précédent ces dernières années, les applications et technologies basées sur l'IA étant de plus en plus répandues dans divers secteurs. Cette expansion rapide de l'IA a entraîné une augmentation correspondante de la demande d'ensembles de données d'entraînement à l'IA de haute qualité, diversifiés et complets pour alimenter ces systèmes avancés. En outre, l'adoption croissante de technologies basées sur l'IA dans des secteurs tels que la santé, la finance, le commerce électronique et les transports a été un facteur majeur de la demande d'ensembles de données d'entraînement à l'IA. Alors que les entreprises et les organisations cherchent à tirer parti de la puissance de l'IA pour améliorer leurs opérations, améliorer la prise de décision et offrir des expériences personnalisées, le besoin d'ensembles de données robustes, fiables et diversifiés pour entraîner ces modèles d'IA a grimpé en flèche. De plus, la popularité croissante et l'adoption généralisée des algorithmes d'apprentissage automatique (ML) et d'apprentissage profond (DL) ont été un facteur important dans la forte augmentation de la demande d'ensembles de données d'entraînement à l'IA. Ces techniques avancées reposent sur de grandes quantités de données pour entraîner leurs modèles, apprendre des schémas et faire des prédictions précises. Par exemple, en Corée du Sud, les données clients sont apparues comme la principale source d'informations pour l'entraînement des modèles d'intelligence artificielle (IA) en 2022, comme l'ont déclaré près de 70 % des entreprises interrogées. En outre, environ 62 % des personnes interrogées ont indiqué qu'elles utilisaient des données internes pour entraîner leurs modèles d'IA.
Tendances du marché des ensembles de données d'entraînement à l'IA
Cette section traite des principales tendances du marché qui influencent les différents segments du marché des ensembles de données d'entraînement à l'IA, telles qu'identifiées par notre équipe d'experts en recherche.
Les ensembles de données au format texte sont actuellement utilisés de manière prédominante pour l'entraînement des modèles d'IA et d'apprentissage automatique et génèrent la majeure partie des revenus de l'industrie des ensembles de données d'entraînement à l'IA.
Les données textuelles sont omniprésentes à l'ère numérique, avec de grandes quantités d'informations disponibles sur Internet, dans les livres, les articles, les médias sociaux et diverses autres sources. Les ensembles de données textuelles sont généralement plus faciles à collecter, à stocker et à traiter que d'autres types de données, tels que l'audio ou la vidéo. En outre, les données textuelles peuvent être utilisées pour entraîner un large éventail de modèles d'IA et d'apprentissage automatique, y compris des modèles de traitement du langage naturel (TLN) pour des tâches telles que l'analyse des sentiments, la classification de texte, la génération de langage et la traduction automatique. Les données textuelles peuvent également être utilisées pour entraîner des modèles pour des tâches au-delà du TLN, telles que la synthèse de documents, la recherche d'informations et même des tâches d'analyse d'images et de vidéos. La polyvalence des données textuelles permet le développement d'une gamme diversifiée d'applications d'IA et d'apprentissage automatique, des robots conversationnels et assistants virtuels aux systèmes de recommandation de contenu et aux outils d'écriture automatisés. De plus, les données textuelles sont généralement moins gourmandes en calcul à traiter que d'autres types de données, telles que les images ou les vidéos haute résolution, qui nécessitent un matériel plus puissant et des ressources de calcul plus importantes. Cela rend les modèles d'IA et d'apprentissage automatique basés sur du texte plus accessibles et plus faciles à développer et à déployer, en particulier sur les appareils à ressources limitées ou dans les scénarios où la puissance de calcul est limitée. Des facteurs tels que ceux-ci favorisent un environnement propice, stimulant la forte augmentation de la demande d'ensembles de données textuelles pour l'entraînement de divers modèles d'IA et d'apprentissage automatique.
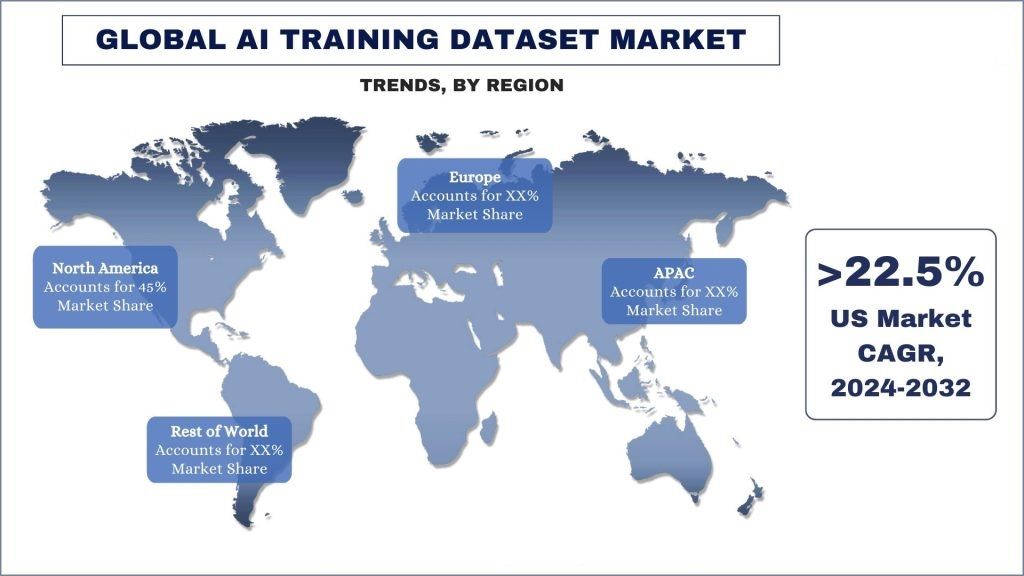
L'Amérique du Nord apparaît comme le marché à la croissance la plus rapide et représente une part importante du marché mondial des ensembles de données d'entraînement à l'IA.
L'Amérique du Nord est devenue l'un des marchés les plus importants et à la croissance la plus rapide pour les ensembles de données d'entraînement à l'IA. Les États-Unis abritent certaines des plus grandes universités de recherche au monde, telles que Stanford, le MIT et Carnegie Mellon, qui ont fait des progrès significatifs dans la recherche sur l'IA et l'apprentissage automatique. En outre, d'importantes entreprises technologiques, notamment Google, Microsoft et Amazon, ont créé des laboratoires de recherche de pointe en IA en Amérique du Nord, stimulant davantage l'innovation et les progrès dans le domaine. De plus, le gouvernement américain a reconnu l'importance stratégique de l'IA et a investi massivement dans le soutien à la recherche et au développement par le biais d'initiatives telles que la National Artificial Intelligence Initiative. De plus, les grandes entreprises technologiques d'Amérique du Nord investissent activement dans la formation et la fidélisation des meilleurs talents en IA et en apprentissage automatique, créant ainsi un cycle d'innovation et de croissance qui s'auto-renforce. Enfin, l'Amérique du Nord, en particulier les États-Unis, abrite un écosystème de capital-risque florissant qui a injecté des milliards de dollars dans des startups et des entreprises d'IA et d'apprentissage automatique. La présence d'importants centres technologiques, tels que la Silicon Valley, Boston et New York, a facilité le flux de capitaux d'investissement vers l'industrie de l'IA et de l'apprentissage automatique. Par exemple, en 2023, selon les données de S&P Global Market Intelligence, les investissements dans les entreprises d'IA générative ont connu une augmentation significative, dépassant le déclin de l'activité globale de fusions et acquisitions. Les sociétés de capital-investissement ont investi 2,18 milliards de dollars US dans l'IA générative, doublant ainsi le total de l'année précédente. Cette poussée de capitaux s'est produite dans un contexte de diminution des transactions de fusions et acquisitions soutenues par des capitaux privés dans tous les secteurs en 2023. Des facteurs tels que ceux-ci ont fait de l'Amérique du Nord une force prédominante dans l'industrie de l'IA et de l'apprentissage automatique, stimulant par conséquent la demande de services d'ensembles de données d'entraînement à l'IA pour soutenir ce taux de croissance sans précédent de l'industrie de l'IA.
Aperçu de l'industrie des ensembles de données d'entraînement à l'IA
Le marché des ensembles de données d'entraînement à l'IA est concurrentiel et fragmenté, avec la présence de plusieurs acteurs du marché mondiaux et internationaux. Les principaux acteurs adoptent différentes stratégies de croissance pour améliorer leur présence sur le marché, telles que des partenariats, des accords, des collaborations, le lancement de nouveaux produits, des expansions géographiques et des fusions et acquisitions. Parmi les principaux acteurs opérant sur le marché figurent Google, Microsoft, Amazon Web Services, Inc., IBM, Oracle, Alegion AI, Inc., TELUS International, Lionbridge Technologies, LLC, Samasource Impact Sourcing, Inc. et Appen Limited.
Actualités du marché des ensembles de données d'entraînement à l'IA
- IBM a dévoilé IBM Watsonx lors de sa conférence annuelle Think le 9 mai 2023. Cette plateforme d'IA et de données révolutionnaire va révolutionner la façon dont les entreprises utilisent l'IA avancée tout en maintenant la fiabilité des données. Avec IBM Watsonx, les organisations peuvent accéder à une pile technologique complète pour la formation, l'affinage et le déploiement de modèles d'IA, y compris des modèles de base et des capacités d'apprentissage automatique. Elle permet également une utilisation transparente des données fiables dans différents environnements cloud, garantissant ainsi la rapidité, la gouvernance et la compatibilité.
- Baidu a dévoilé en avril 2024 un ensemble de nouveaux outils d'IA conçus pour permettre aux personnes sans expertise en codage de développer des robots conversationnels génératifs basés sur l'IA et adaptés à des fins particulières. Ces robots conversationnels peuvent ensuite être intégrés à un site Web, aux résultats du moteur de recherche Baidu ou à d'autres plateformes en ligne.
Couverture du rapport sur le marché des ensembles de données d'entraînement à l'IA
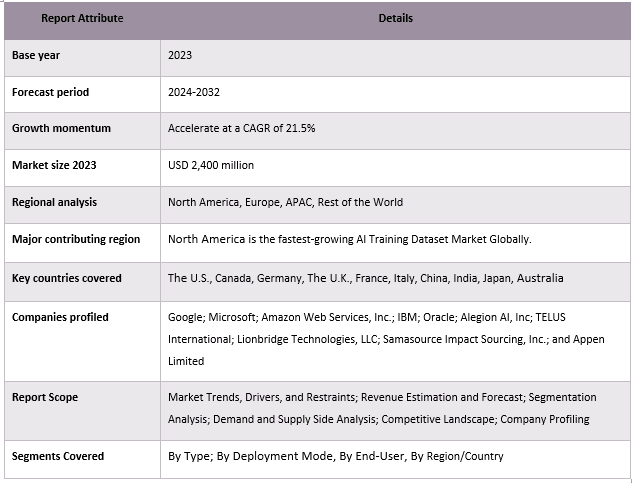
Couverture du rapport sur le marché des ensembles de données d'entraînement à l'IA
Raisons d'acheter ce rapport :
- L'étude comprend une analyse de la taille et des prévisions du marché validée par des experts clés authentifiés de l'industrie.
- Le rapport présente un aperçu rapide de la performance globale de l'industrie en un coup d'œil.
- Le rapport couvre une analyse approfondie des principaux pairs de l'industrie en mettant l'accent sur les principales données financières de l'entreprise, les portefeuilles de produits, les stratégies d'expansion et les développements récents.
- Examen détaillé des moteurs, des contraintes, des principales tendances et des opportunités qui prévalent dans l'industrie.
- L'étude couvre de manière exhaustive le marché dans différents segments.
- Analyse approfondie au niveau régional de l'industrie.
Options de personnalisation :
Le marché mondial des ensembles de données d'entraînement à l'IA peut être personnalisé davantage en fonction des besoins ou de tout autre segment de marché. En outre, UMI comprend que vous pouvez avoir vos propres besoins commerciaux ; n'hésitez donc pas à nous contacter pour obtenir un rapport qui correspond parfaitement à vos besoins.
Table des matières
Méthodologie de recherche pour l'analyse du marché des ensembles de données d'entraînement à l'IA (2024-2032)
L'analyse du marché historique, l'estimation du marché actuel et la prévision du marché futur du marché mondial des ensembles de données d'entraînement à l'IA ont été les trois principales étapes entreprises pour créer et analyser l'adoption des ensembles de données d'entraînement à l'IA dans les principales régions du monde. Une recherche secondaire exhaustive a été menée pour collecter les chiffres du marché historique et estimer la taille du marché actuel. Deuxièmement, pour valider ces informations, de nombreuses conclusions et hypothèses ont été prises en considération. De plus, des entretiens primaires exhaustifs ont également été menés avec des experts de l'industrie à travers la chaîne de valeur du marché mondial des ensembles de données d'entraînement à l'IA. Après l'hypothèse et la validation des chiffres du marché par le biais d'entretiens primaires, nous avons utilisé une approche descendante/ascendante pour prévoir la taille complète du marché. Par la suite, des méthodes de ventilation du marché et de triangulation des données ont été adoptées pour estimer et analyser la taille du marché des segments et sous-segments de l'industrie. La méthodologie détaillée est expliquée ci-dessous :
Analyse de la taille du marché historique
Étape 1 : Étude approfondie des sources secondaires :
Une étude secondaire détaillée a été menée pour obtenir la taille du marché historique du marché des ensembles de données d'entraînement à l'IA à partir de sources internes à l'entreprise, telles que les rapports annuels et états financiers, présentations de performance, communiqués de presse, etc., et de sources externes, notamment les revues, actualités et articles, publications gouvernementales, publications des concurrents, rapports sectoriels, bases de données tierces et autres publications crédibles.
Étape 2 : Segmentation du marché :
Après avoir obtenu la taille du marché historique du marché des ensembles de données d'entraînement à l'IA, nous avons mené une analyse secondaire détaillée pour recueillir des informations sur le marché historique et partager les différents segments et sous-segments pour les principales régions. Les principaux segments inclus dans le rapport sont le type, le mode de déploiement et l'utilisateur final. D'autres analyses au niveau des pays ont été menées pour évaluer l'adoption globale des modèles de test dans cette région.
Étape 3 : Analyse des facteurs :
Après avoir acquis la taille du marché historique des différents segments et sous-segments, nous avons mené une analyse des facteurs détaillée pour estimer la taille actuelle du marché des ensembles de données d'entraînement à l'IA. De plus, nous avons mené une analyse des facteurs à l'aide de variables dépendantes et indépendantes telles que le type, le mode de déploiement et l'utilisateur final du marché des ensembles de données d'entraînement à l'IA. Une analyse approfondie a été menée des scénarios de demande et d'offre en tenant compte des principaux partenariats, fusions et acquisitions, expansion commerciale et lancements de produits dans le secteur du marché des ensembles de données d'entraînement à l'IA à travers le monde.
Estimation et prévision de la taille actuelle du marché
Détermination de la taille actuelle du marché : Sur la base des informations exploitables des 3 étapes ci-dessus, nous sommes parvenus à la taille actuelle du marché, aux principaux acteurs du marché mondial des ensembles de données d'entraînement à l'IA et aux parts de marché des segments. Tous les pourcentages de parts requis et les ventilations du marché ont été déterminés à l'aide de l'approche secondaire susmentionnée et ont été vérifiés par le biais d'entretiens primaires.
Estimation et prévision : Pour l'estimation et la prévision du marché, des pondérations ont été attribuées à différents facteurs, notamment les moteurs et les tendances, les contraintes et les opportunités disponibles pour les parties prenantes. Après avoir analysé ces facteurs, des techniques de prévision pertinentes, c'est-à-dire l'approche descendante/ascendante, ont été appliquées pour parvenir à la prévision du marché pour 2032 pour différents segments et sous-segments à travers les principaux marchés mondiaux. La méthodologie de recherche adoptée pour estimer la taille du marché comprend :
- La taille du marché de l'industrie, en termes de chiffre d'affaires (USD) et le taux d'adoption du marché des ensembles de données d'entraînement à l'IA sur les principaux marchés nationaux
- Tous les pourcentages de parts, les divisions et les ventilations des segments et sous-segments du marché
- Les principaux acteurs du marché mondial des ensembles de données d'entraînement à l'IA en termes de produits offerts. De plus, les stratégies de croissance adoptées par ces acteurs pour concurrencer sur le marché à croissance rapide.
Validation de la taille et de la part du marché
Recherche primaire : Des entretiens approfondis ont été menés avec les principaux leaders d'opinion (KOL), notamment les cadres supérieurs (CXO/VP, responsable des ventes, responsable du marketing, responsable des opérations, responsable régional, responsable pays, etc.) dans les principales régions. Les résultats de la recherche primaire ont ensuite été résumés, et une analyse statistique a été effectuée pour prouver l'hypothèse énoncée. Les contributions de la recherche primaire ont été regroupées avec les résultats secondaires, transformant ainsi l'information en informations exploitables.
Répartition des participants primaires dans différentes régions
Ingénierie du marché
La technique de triangulation des données a été utilisée pour compléter l'estimation globale du marché et pour parvenir à des chiffres statistiques précis pour chaque segment et sous-segment du marché mondial des ensembles de données d'entraînement à l'IA. Les données ont été divisées en plusieurs segments et sous-segments après avoir étudié divers paramètres et tendances dans les domaines du type, du mode de déploiement et de l'utilisateur final sur le marché mondial des ensembles de données d'entraînement à l'IA.
L'objectif principal de l'étude du marché mondial des ensembles de données d'entraînement à l'IA
Les tendances actuelles et futures du marché mondial des ensembles de données d'entraînement à l'IA ont été mises en évidence dans l'étude. Les investisseurs peuvent obtenir des informations stratégiques pour baser leur discrétion en matière d'investissements sur l'analyse qualitative et quantitative effectuée dans l'étude. Les tendances actuelles et futures du marché ont déterminé l'attractivité globale du marché au niveau régional, offrant une plateforme aux participants industriels pour exploiter le marché inexploité afin de bénéficier d'un avantage de premier arrivé. Les autres objectifs quantitatifs des études comprennent :
- Analyser la taille actuelle et prévisionnelle du marché des ensembles de données d'entraînement à l'IA en termes de valeur (USD). De plus, analyser la taille actuelle et prévisionnelle du marché des différents segments et sous-segments.
- Les segments de l'étude comprennent les domaines du type, du mode de déploiement et de l'utilisateur final
- Définir et analyser le cadre réglementaire pour l'IA Training Dataset
- Analyser la chaîne de valeur impliquée avec la présence de divers intermédiaires, ainsi qu'analyser les comportements des clients et des concurrents de l'industrie
- Analyser la taille actuelle et prévisionnelle du marché des ensembles de données d'entraînement à l'IA pour la région principale
- Les principaux pays des régions étudiées dans le rapport comprennent l'Asie-Pacifique, l'Europe, l'Amérique du Nord et le reste du monde
- Profils d'entreprises du marché des ensembles de données d'entraînement à l'IA et stratégies de croissance adoptées par les acteurs du marché pour se maintenir sur le marché à croissance rapide.
- Analyse approfondie au niveau régional de l'industrie
Questions Fréquemment Posées FAQ
Q1 : Quelle est la taille actuelle du marché et le potentiel de croissance du marché mondial des ensembles de données d'entraînement pour l'IA ?
Q2 : Quels sont les principaux facteurs de croissance du marché mondial des ensembles de données d'entraînement pour l'IA ?
Q3 : Quel segment détient la part la plus importante du marché mondial des ensembles de données d'entraînement à l'IA par utilisateur final ?
Q4 : Quelles sont les technologies émergentes et les tendances du marché mondial des ensembles de données d'entraînement pour l'IA ?
Q5 : Quelle région connaîtra la croissance la plus rapide sur le marché mondial des ensembles de données d’entraînement pour l’IA ?
Q6 : Quels sont les principaux acteurs du marché mondial des ensembles de données d'entraînement pour l'IA ?
Connexes Rapports
Les clients qui ont acheté cet article ont également acheté





Marché des services informatiques et BPO en Inde : Analyse actuelle et prévisions (2026-2034)
Accent sur le type de service (services informatiques, services BPO, services d'ingénierie et de R&D) ; type d'externalisation (sur site, offshore, nearshore) ; taille de l'organisation (grandes entreprises, PME) ; secteur d'activité de l'utilisateur final (BFSI, informatique et télécommunications, santé, vente au détail et commerce électronique, fabrication, autres) ; et région/états

Marché de la technologie Gi-Fi : Analyse actuelle et prévisions (2025-2033)
Accent mis sur le type de produit (dispositifs d'affichage et dispositifs d'infrastructure réseau) ; la technologie (système sur puce et puce de circuit intégré) ; l'application (électronique grand public, commerce et mise en réseau) ; et la région/le pays

Marché du stockage de données ADN : Analyse actuelle et prévisions (2026-2034)
Accent sur le type (Cloud et sur site) ; Technologie (Stockage de données ADN basé sur la séquence et Stockage de données ADN basé sur la structure) ; Utilisateur final (Gouvernement, Santé et biotechnologie, Médias et télécommunications, et Autres) ; et Région/Pays

Marché du courtage de services cloud : Analyse actuelle et prévisions (2026-2034)
Accent mis sur le type de service (Intégration et support, Automatisation et orchestration, Facturation et mise en service, Migration et personnalisation, Sécurité et conformité, et autres) ; Plateforme (Activation du courtage interne et Activation du courtage externe) ; Déploiement (Privé, Public et Hybride) ; Taille de l’entreprise (Grandes entreprises et Petites et moyennes entreprises) ; Utilisation finale (IT & Télécom, BFSI, Secteur public et gouvernemental, Santé, Biens de consommation et vente au détail, Fabrication, Énergie et services publics, et autres) ; et Région/Pays

