自然言語処理市場:現状分析と予測(2021年~2027年)
タイプ(ルールベース、統計、ハイブリッド)の重視、アプリケーション(情報抽出、機械翻訳、質問応答、レポート生成、その他)、デプロイメント(オンプレミス、クラウド)、アプリケーション(BFSI、ヘルスケア、IT・通信、小売、その他)、地域/国
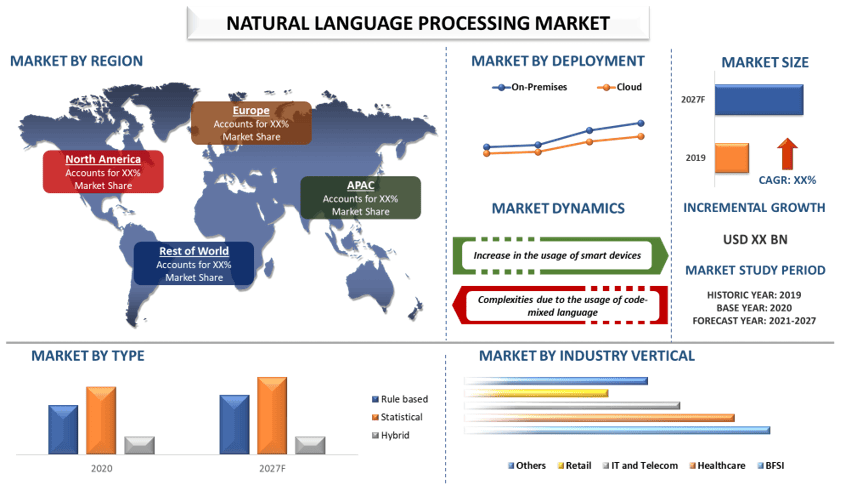
自然言語処理市場は、予測期間中に年平均成長率24.%で成長すると予想されています。 スマートデバイスの利用増加によるインテリジェントな環境の推進は、予測期間中の自然言語処理(NLP)市場の成長に影響を与えると予想されます。クラウドベースのNLPソリューションに対する需要の高まりにより、全体的なコスト削減と拡張性が向上することも、自然言語処理(NLP)市場の成長を後押しすると予想されます。さらに、リスクを軽減し、成長の機会を特定するための予測分析の急速な推進も、市場の成長にプラスの影響を与える可能性があります。また、世界中でITと自動化の規模と利用が急速に拡大することにより、自然言語処理(NLP)に対する大きな需要が生まれ、自然言語処理(NLP)市場の成長を促進すると予想されます。自然言語処理は、テクノロジーと人間の間のコミュニケーションギャップを埋めます。その導入により、人間は理解しやすい指示を与えることができるようになりました。また、人間の言語を理解、解釈、操作する人工知能の一分野とも考えられています。
レポートで提示される洞察
「タイプ別では、統計セグメントが予測期間中に最も高いCAGRを示すと予想されます」
タイプに基づいて、市場はルールベース、統計、およびハイブリッドにセグメント化されています。統計セグメントは、自然言語処理市場の大部分を占めると予想されます。統計的自然言語処理(NLP)は、自然言語処理の分野で統計的推論を実行することを目的としています。統計的NLPは、チャットボットと人間との自然な会話も可能にします。
「アプリケーション別では、機械翻訳セグメントが予測期間中に最も高いCAGRを示すと予想されます」
アプリケーションに基づいて、市場は情報抽出、機械翻訳、質問応答、レポート生成、およびその他にセグメント化されています。機械翻訳市場は、テキストを複数の言語に翻訳できるソリューションに対する組織の需要が高まっているため、自然言語処理市場の大部分を占めると予想されます。
「展開別では、クラウドセグメントが予測期間中に最も高いCAGRを示すと予想されます」
展開に基づいて、市場はオンプレミスとクラウドにセグメント化されています。クラウドセグメントは、自然言語処理市場の大部分を占めると予想されます。クラウドベースの自然言語処理プラットフォームを使用すると、ユーザーは多言語コンテンツ、ユーザー生成コンテンツ、その他のWebコンテンツをより安全な方法で利用および分析でき、世界中のどこからでもこのデータにアクセスできます。
「北米は予測期間中に大幅な成長を遂げると予想されます」
北米市場は、予測期間中に最も高いCAGRを保持すると予想されます。北米は最も発展した地域の1つであり、分析、AI、MLなどのテクノロジーに多額の投資を行っています。米国の多くのスタートアップ企業は、自然言語処理サービスを徐々に展開しています。さらに、多くのスタートアップ企業が米国などの国のNLP市場に参入しています。これは、市場に存在するAIおよびNLP対応の製品およびソリューションに対する需要が高まっているためです。米国が最大の市場シェアを占めており、世界のNLP市場で最も収益性の高い地域です。インフラストラクチャの急速な発展とデジタルテクノロジーの高い採用は、この地域のNLP市場の成長を促進する主な要因です。
このレポートを購入する理由:
- この調査には、認証された主要な業界専門家によって検証された市場規模と予測分析が含まれています。
- レポートは、全体的な業界パフォーマンスの簡単なレビューを一目で示しています。
- レポートは、主要なビジネス財務、製品ポートフォリオ、拡張戦略、および最近の開発に主な焦点を当てて、著名な業界ピアの詳細な分析をカバーしています。
- 業界で普及しているドライバー、制約、主要なトレンド、および機会の詳細な調査。
- この調査は、さまざまなセグメントにわたる市場を包括的にカバーしています。
- 業界の地域レベルの詳細な分析。
カスタマイズオプション:
グローバルな自然言語処理市場は、要件またはその他の市場セグメントに応じて、さらにカスタマイズできます。これに加えて、UMIは、お客様が独自のビジネスニーズを持っている可能性があることを理解しているため、お客様の要件に完全に適合するレポートを入手するためにお気軽にお問い合わせください。
目次
グローバル自然言語処理市場分析(2021年~2027年)の調査方法
グローバル自然言語処理市場の過去の市場を分析し、現在の市場を推定し、将来の市場を予測することは、世界の主要地域における自然言語処理の採用を構築し分析するために行われた3つの主要なステップでした。 過去の市場規模を収集し、現在の市場規模を推定するために、徹底的な二次調査が実施されました。 次に、これらの洞察を検証するために、多数の調査結果と仮定が考慮されました。 さらに、グローバル自然言語処理市場のバリューチェーン全体にわたる業界の専門家との徹底的な一次インタビューも実施されました。 一次インタビューを通じて市場規模の仮定と検証を行った後、トップダウン/ボトムアップアプローチを採用して、市場規模全体を予測しました。 その後、市場の細分化とデータ三角測量法を採用して、業界に関連するセグメントおよびサブセグメントの市場規模を推定および分析しました。 詳細な方法論は以下に説明します。
過去の市場規模の分析
ステップ1:二次資料の詳細な調査:
自然言語処理市場の過去の市場規模を取得するために、年次報告書と財務諸表、業績プレゼンテーション、プレスリリースなどの企業内情報源、およびジャーナル、ニュース&記事、政府刊行物、競合他社の刊行物、セクターレポート、サードパーティデータベース、その他の信頼できる刊行物などの外部情報源を通じて、詳細な二次調査を実施しました。
ステップ2:市場セグメンテーション:
自然言語処理市場の過去の市場規模を取得した後、主要地域のさまざまなセグメントとサブセグメントに関する過去の市場の洞察とシェアを収集するために、詳細な二次分析を実施しました。 主要なセグメントは、種類、アプリケーション、デプロイメント、業界の垂直市場としてレポートに含まれています。 さらに、その地域でのテストモデルの全体的な採用を評価するために、国レベルの分析を実施しました。
ステップ3:要因分析:
さまざまなセグメントとサブセグメントの過去の市場規模を取得した後、自然言語処理市場の現在の市場規模を推定するために、詳細な要因分析を実施しました。 さらに、自然言語処理のさまざまなタイプ、アプリケーション、デプロイメント、および業界の垂直市場などの依存変数と独立変数を使用して、要因分析を実施しました。 世界中の自然言語処理市場セクターにおける主要なパートナーシップ、合併と買収、事業拡大、および製品の発売を考慮して、需要と供給側のシナリオについて徹底的な分析を実施しました。
現在の市場規模の推定と予測
現在の市場規模:上記の3つのステップからの実用的な洞察に基づいて、現在の市場規模、グローバル自然言語処理市場の主要なプレーヤー、およびセグメントの市場シェアに到達しました。 必要な割合のシェアの分割、および市場の内訳はすべて、上記の二次的なアプローチを使用して決定され、一次インタビューを通じて検証されました。
推定と予測:市場の推定と予測のために、ドライバーとトレンド、制約、および利害関係者が利用できる機会を含むさまざまな要因に重みが割り当てられました。 これらの要因を分析した後、関連する予測手法、つまりトップダウン/ボトムアップアプローチを適用して、世界の主要市場全体のさまざまなセグメントおよびサブセグメントについて、2027年頃の市場予測に到達しました。 市場規模の推定に採用された調査方法には、以下が含まれます。
- 収益(米ドル)および国内の主要市場全体での自然言語処理市場の採用率の観点からの業界の市場規模
- 市場セグメントとサブセグメントのすべての割合シェア、分割、および内訳
- 提供されるソリューションの観点から見た、グローバル自然言語処理市場の主要プレーヤー。 また、急速に成長する市場で競争するためにこれらのプレーヤーが採用した成長戦略
市場規模とシェアの検証
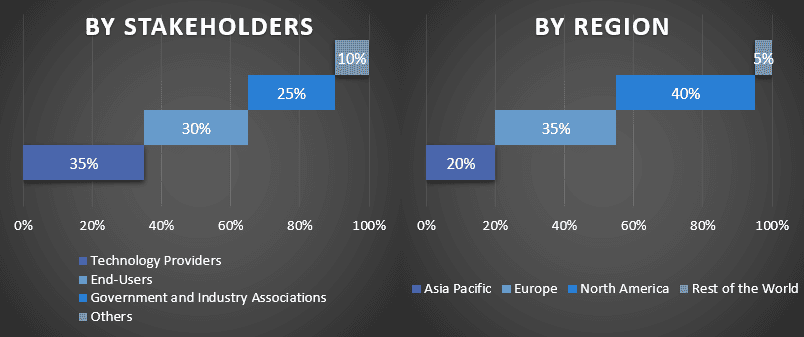
一次調査:主要地域全体のトップレベルのエグゼクティブ(CXO / VP、営業部長、マーケティング部長、運営部長、地域部長、国部長など)を含む主要なオピニオンリーダー(KOL)との詳細なインタビューを実施しました。 次に、一次調査の結果を要約し、統計分析を実施して、述べられた仮説を証明しました。 一次調査からのインプットは二次的な調査結果と統合され、それによって情報が実用的な洞察に変わりました。
さまざまな地域における一次参加者の分割
市場エンジニアリング
グローバル自然言語処理市場の各セグメントおよびサブセグメントの正確な統計数値を把握し、全体的な市場の推定を完了するために、データ三角測量法を採用しました。 グローバル自然言語処理市場におけるタイプ、アプリケーション、およびデプロイメント、業界の垂直市場の分野におけるさまざまなパラメーターとトレンドを調査した後、データをいくつかのセグメントとサブセグメントに分割しました。
グローバル自然言語処理市場調査の主な目的
グローバル自然言語処理市場の現在および将来の市場動向は、調査で正確に指摘されました。 投資家は、調査で実施された定性的および定量的分析に基づいて、投資に関する裁量を判断するための戦略的な洞察を得ることができます。 現在および将来の市場動向は、地域レベルでの市場の全体的な魅力を決定し、産業参加者が未開発の市場を利用してファーストムーバーの優位性を活用するためのプラットフォームを提供しました。 調査のその他の定量的な目標には、以下が含まれます。
- 価値(米ドル)の観点から見た、自然言語処理市場の現在および予測される市場規模を分析します。 また、さまざまなセグメントとサブセグメントの現在および予測される市場規模を分析します
- 調査のセグメントには、タイプ、アプリケーション、デプロイメント、および業界の垂直市場の分野が含まれます。
- 自然言語処理市場業界の規制の枠組みを定義し、分析します。
- 業界の顧客と競合他社の行動を分析するとともに、さまざまな仲介業者の存在に伴うバリューチェーンを分析します。
- 主要地域の自然言語処理市場の現在および予測される市場規模を分析します。
- レポートで調査された地域の主要国には、アジア太平洋、ヨーロッパ、北米、および世界のその他の地域が含まれます。
- 自然言語処理市場の企業プロファイルと、急速に成長する市場で持続するために市場プレーヤーが採用した成長戦略
- 業界の詳細な地域レベルの分析
関連 レポート
この商品を購入したお客様はこれも購入しました





インドITおよびBPOサービス市場:現状分析と予測(2026-2034年)
サービスタイプ(ITサービス、BPOサービス、エンジニアリング&R&Dサービス)、アウトソーシングタイプ(オンショア、オフショア、ニアショア)、組織規模(大企業、中小企業)、エンドユーザー産業(BFSI、IT&通信、ヘルスケア、小売&Eコマース、製造、その他)、および地域/州への重点

Gi-Fi技術市場:現在の分析と予測(2025年~2033年)
製品タイプ(ディスプレイデバイス、ネットワークインフラストラクチャデバイス); テクノロジー(システムオンチップ、集積回路チップ); アプリケーション(家電、商業、ネットワーキング); 地域/国

DNAデータストレージ市場:現状分析と予測(2026年~2034年)
タイプ別(クラウドおよびオンプレミス)、テクノロジー別(シーケンスベースDNAデータストレージおよび構造ベースDNAデータストレージ)、エンドユーザー別(政府、ヘルスケア&バイオテクノロジー、メディア&テレコミュニケーション、その他)、および地域/国別

クラウドサービスブローカレッジ市場:現状分析と予測(2026年~2034年)
サービスタイプ(統合とサポート、自動化とオーケストレーション、請求とプロビジョニング、移行とカスタマイズ、セキュリティとコンプライアンス、その他)の重視; プラットフォーム(内部ブローカレッジイネーブルメントおよび外部ブローカレッジイネーブルメント); デプロイメント(プライベート、パブリック、およびハイブリッド); 企業規模(大企業、および中小企業); エンドユース(IT&通信、BFSI、政府&公共部門、ヘルスケア、消費財&小売、製造、エネルギー&公益事業、その他); および地域/国

