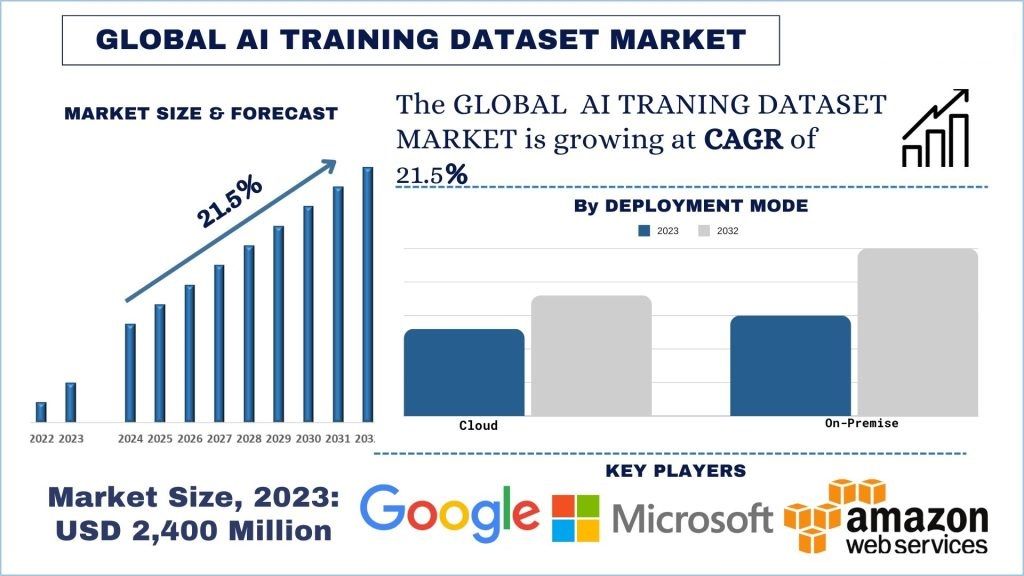
人工智能训练数据集市场规模与预测
人工智能训练数据集市场价值为 24 亿美元,预计在预测期内(2024-2032 年)将以 21.5% 左右的强劲复合年增长率增长,这归因于人工智能和机器学习应用程序开发和部署的日益普及。
人工智能训练数据集市场分析
人工智能训练数据集是用于训练和开发机器学习和人工智能模型的基础数据。这些数据集包含带标签的示例,人工智能模型使用这些示例来学习模式和关系并做出准确的预测。数据集从各种来源收集,例如数据库、网站、文章、视频脚本、社交媒体和其他相关数据源。目的是收集多样化且具有代表性的数据集。原始数据经过仔细标记和注释,以便为人工智能模型提供准确的学习信息。这包括对数据进行分类、标记和描述。

近年来,人工智能 (AI) 领域取得了前所未有的增长和进步,人工智能驱动的应用程序和技术在各个行业中变得越来越普遍。人工智能的快速扩张导致对高质量、多样化和全面的 AI 训练数据集的需求相应激增,以支持这些先进系统。此外,医疗保健、金融、电子商务和交通运输等行业越来越多地采用 AI 驱动的技术,这已成为 AI 训练数据集需求的主要驱动因素。随着公司和组织寻求利用人工智能的力量来加强运营、改进决策并提供个性化体验,对稳健、可靠和多样化的数据集的需求也随之猛增,以便训练这些人工智能模型。此外,机器学习 (ML) 和深度学习 (DL) 算法的日益普及和广泛采用也是人工智能训练数据集需求激增的重要因素。这些先进技术依赖大量数据来训练其模型、学习模式并做出准确的预测。例如,在韩国,客户数据已成为 2022 年训练人工智能 (AI) 模型的主要信息来源,近 70% 的受访公司表示。此外,约 62% 的受访者表示他们利用内部数据来训练其人工智能模型。
人工智能训练数据集市场趋势
本节讨论了影响人工智能训练数据集市场各个细分市场的关键市场趋势,这些趋势由我们的研究专家团队确定。
目前,文本格式的数据集主要用于训练人工智能和机器学习模型,并为人工智能训练数据集行业创造了大部分收入。
在数字时代,文本数据无处不在,互联网、书籍、文章、社交媒体和各种其他来源都提供了大量信息。与其他数据类型(例如音频或视频)相比,文本数据集通常更容易收集、存储和处理。此外,文本数据可用于训练各种人工智能和机器学习模型,包括自然语言处理 (NLP) 模型,用于情感分析、文本分类、语言生成和机器翻译等任务。文本数据还可用于训练用于 NLP 以外任务的模型,例如文档摘要、信息检索,甚至图像和视频分析任务。文本数据的多功能性允许开发各种人工智能和机器学习应用程序,从聊天机器人和虚拟助手到内容推荐系统和自动写作工具。此外,与其他数据类型(例如高分辨率图像或视频)相比,文本数据的计算密集程度通常较低,后者需要更强大的硬件和更大的计算资源。这使得基于文本的人工智能和机器学习模型更易于访问,更易于开发和部署,尤其是在资源受限的设备上或计算能力有限的情况下。诸如此类的因素正在营造有利的环境,从而推动了对用于训练各种人工智能和机器学习模型的文本数据集的需求激增。
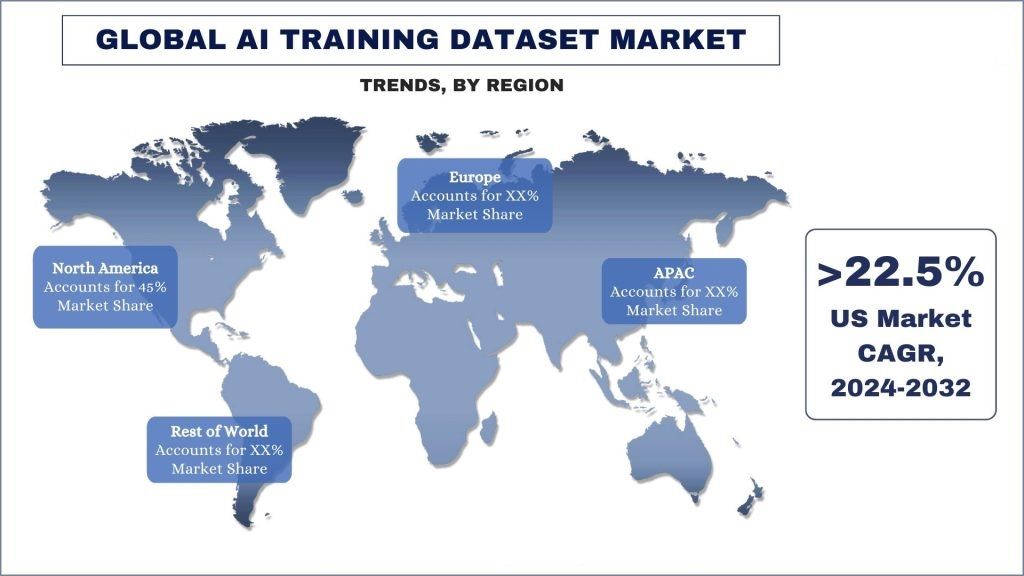
北美正在成为增长最快的市场,并在全球人工智能训练数据集市场中占据重要份额。
北美已成为人工智能训练数据集最大且增长最快的市场之一。美国拥有一些世界领先的研究型大学,例如斯坦福大学、麻省理工学院和卡内基梅隆大学,这些大学在人工智能和机器学习研究方面取得了重大进展。此外,包括谷歌、微软和亚马逊在内的知名科技公司已在北美建立了尖端的人工智能研究实验室,进一步推动了该领域的创新和进步。此外,美国政府已经认识到人工智能的战略重要性,并通过国家人工智能倡议等举措大力投资于支持研发。此外,北美的主要科技公司一直在积极投资于培训和留住顶尖的人工智能和机器学习人才,从而创造了一个自我强化的创新和增长循环。最后,北美,尤其是美国,拥有蓬勃发展的风险投资生态系统,已向人工智能和机器学习初创公司和公司投入了数十亿美元。硅谷、波士顿和纽约等主要科技中心的出现促进了投资资本流入人工智能和机器学习行业。例如,根据标准普尔全球市场情报公司的数据,2023 年,对生成式人工智能公司的投资大幅增加,超过了并购活动总体下滑的幅度。私募股权公司在生成式人工智能领域投资了 21.8 亿美元,是上一年总额的两倍。在 2023 年各行业的私募股权支持的并购交易减少的情况下,资本激增。诸如此类的因素使北美成为人工智能和机器学习领域的主导力量,从而推动了对人工智能训练数据集服务的需求,以支持人工智能行业前所未有的增长速度。
人工智能训练数据集行业概况
人工智能训练数据集市场竞争激烈且分散,存在多家全球和国际市场参与者。主要参与者正在采取不同的增长战略来提高其市场地位,例如伙伴关系、协议、合作、新产品发布、地域扩张以及兼并和收购。市场上运营的一些主要参与者包括 Google、Microsoft、Amazon Web Services, Inc.、IBM、Oracle、Alegion AI, Inc.、TELUS International、Lionbridge Technologies, LLC、Samasource Impact Sourcing, Inc. 和 Appen Limited。
人工智能训练数据集市场新闻
- IBM 在 2023 年 5 月 9 日举行的年度 Think 大会上推出了 IBM Watsonx。这款突破性的人工智能和数据平台将彻底改变企业利用高级人工智能的方式,同时保持数据的可靠性。借助 IBM Watsonx,组织可以访问全面的技术堆栈,用于训练、微调和部署人工智能模型,包括基础模型和机器学习功能。它还可以无缝利用不同云环境中的可信数据,从而确保速度、治理和兼容性。
- 百度在 2024 年 4 月推出了一套新的人工智能工具,旨在使没有编码专业知识的个人能够开发针对特定目的量身定制的生成式人工智能驱动的聊天机器人。这些聊天机器人随后可以集成到网站、百度搜索引擎结果或其他在线平台中。
人工智能训练数据集市场报告覆盖范围
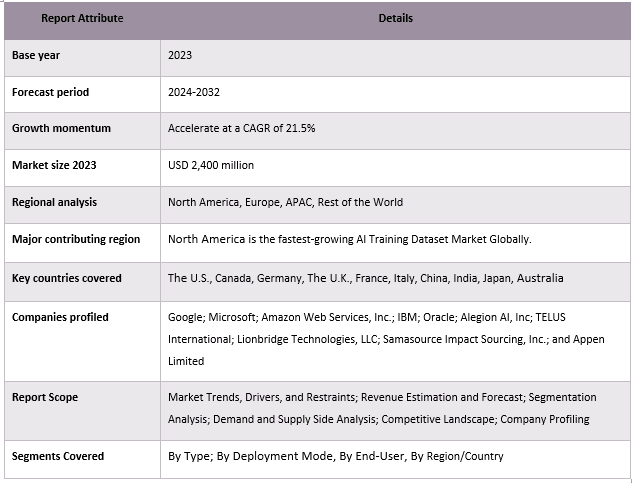
人工智能训练数据集市场报告覆盖范围
购买本报告的理由:
- 该研究包括经过认证的关键行业专家验证的市场规模和预测分析。
- 该报告快速回顾了整个行业的整体表现。
- 该报告深入分析了卓越的行业同行,主要关注关键业务财务、产品组合、扩张战略和最新发展。
- 详细考察了行业中存在的驱动因素、制约因素、关键趋势和机遇。
- 该研究全面涵盖了跨不同细分市场的市场。
- 深入的行业区域层面分析。
定制选项:
可以根据要求或任何其他细分市场进一步定制全球人工智能训练数据集市场。除此之外,UMI 了解到您可能有自己的业务需求;因此,请随时与我们联系以获取完全满足您要求的报告。
目录
AI训练数据集市场分析(2024-2032)的研究方法
分析历史市场、评估当前市场以及预测全球AI训练数据集市场的未来市场是创建和分析全球主要地区AI训练数据集应用情况的三个主要步骤。进行了详尽的二级研究,以收集历史市场数据并评估当前市场规模。其次,为了验证这些见解,考虑了许多发现和假设。此外,还与全球AI训练数据集市场价值链上的行业专家进行了详尽的初步访谈。在通过初步访谈对市场数据进行假设和验证后,我们采用了自上而下/自下而上的方法来预测完整的市场规模。此后,采用市场细分和数据三角测量方法来评估和分析行业细分市场和子细分市场的市场规模。详细的方法如下所述:
历史市场规模分析
第一步:深入研究二级来源:
进行了详细的二级研究,通过公司内部来源(如年度报告和财务报表、业绩演示、新闻稿等)以及外部来源(包括期刊、新闻和文章、政府出版物、竞争对手出版物、行业报告、第三方数据库和其他可靠的出版物)获取AI训练数据集市场的历史市场规模。
第二步:市场细分:
在获得AI训练数据集市场的历史市场规模后,我们进行了详细的二级分析,以收集主要地区不同细分市场和子细分市场的历史市场见解和份额。报告中包含的主要细分市场包括类型、部署模式和最终用户。此外,还进行了国家/地区层面的分析,以评估该地区测试模型的总体应用情况。
第三步:因素分析:
在获得不同细分市场和子细分市场的历史市场规模后,我们进行了详细的因素分析,以评估AI训练数据集市场的当前市场规模。此外,我们使用AI训练数据集市场的类型、部署模式和最终用户等相关和独立变量进行了因素分析。我们对需求和供应侧情景进行了彻底的分析,考虑了全球AI训练数据集市场领域的顶级合作伙伴关系、并购、业务扩张和产品发布。
当前市场规模评估和预测
当前市场规模:根据以上3个步骤的可行见解,我们得出了当前的市场规模、全球AI训练数据集市场的关键参与者以及细分市场的市场份额。所有必需的百分比份额拆分和市场细分均使用上述二级方法确定,并通过初步访谈进行了验证。
评估和预测:对于市场评估和预测,对包括驱动因素和趋势、限制因素以及利益相关者可获得的机会在内的不同因素分配了权重。在分析了这些因素之后,应用了相关的预测技术,即自上而下/自下而上的方法,以得出2032年全球主要市场不同细分市场和子细分市场的市场预测。用于评估市场规模的研究方法包括:
- 该行业的市场规模,以收入(美元)和国内主要市场中AI训练数据集市场的采用率衡量
- 所有百分比份额、拆分以及市场细分和子细分的细分
- 全球AI训练数据集市场中的主要参与者,按提供的产品划分。此外,这些参与者为在快速增长的市场中竞争而采取的增长策略。
市场规模和份额验证
初步研究:与主要地区的关键意见领袖 (KOL) 进行了深入访谈,包括高层管理人员(CXO/VP、销售主管、市场主管、运营主管、区域主管、国家主管等)。然后总结了初步研究结果,并进行了统计分析以证明所述假设。初步研究的输入与二级研究结果合并,从而将信息转化为可操作的见解。
不同地区的主要参与者构成
市场工程
采用数据三角测量技术来完成整体市场评估,并获得全球AI训练数据集市场各个细分市场和子细分市场的精确统计数据。在研究了全球AI训练数据集市场中类型、部署模式和最终用户等领域的各种参数和趋势之后,将数据分成多个细分市场和子细分市场。
全球AI训练数据集市场研究的主要目标
该研究指出了全球AI训练数据集市场的当前和未来市场趋势。投资者可以获得战略见解,以根据研究中执行的定性和定量分析来决定投资方向。当前和未来的市场趋势决定了市场在区域层面的整体吸引力,为行业参与者提供了一个利用未开发市场以从先发优势中受益的平台。研究的其他量化目标包括:
- 分析AI训练数据集市场的当前和预测市场规模(按价值(美元)计算)。此外,分析不同细分市场和子细分市场的当前和预测市场规模。
- 研究中的细分市场包括类型、部署模式和最终用户领域
- 定义和分析AI训练数据集的监管框架
- 分析涉及各种中介机构的价值链,并分析行业客户和竞争对手的行为
- 分析主要地区AI训练数据集市场的当前和预测市场规模
- 报告中研究的主要区域国家/地区包括亚太地区、欧洲、北美和世界其他地区
- AI训练数据集市场的公司概况以及市场参与者为在快速增长的市场中保持竞争力而采取的增长策略。
- 深入分析该行业的区域层面
常见问题 常见问题
Q1:全球人工智能训练数据集市场目前的市场规模和增长潜力是什么?
Q2:全球人工智能训练数据集市场增长的驱动因素有哪些?
Q3:按最终用户划分,哪个细分市场占据全球AI训练数据集市场的主要份额?
Q4:全球人工智能训练数据集市场的新兴技术和趋势有哪些?
Q5:哪个地区将是全球人工智能训练数据集市场增长最快的地区?
Q6:全球AI训练数据集市场的主要参与者有哪些?
相关 报告
购买此商品的客户也购买了





印度IT和BPO服务市场:当前分析与预测(2026-2034年)
服务类型(IT服务、BPO服务、工程研发服务)、外包类型( onshore、offshore、nearshore)、组织规模(大型企业、中小企业)、最终用户行业(BFSI、IT与电信、医疗保健、零售与电子商务、制造业、其他)以及地区/州

Gi-Fi技术市场:当前分析与预测(2025-2033年)
侧重产品类型(显示设备和网络基础设施设备);技术(片上系统和集成电路芯片);应用(消费电子、商业和网络);以及区域/国家

DNA数据存储市场:当前分析与预测 (2026-2034)
类型侧重(云和本地部署);技术(基于序列的DNA数据存储和基于结构的DNA数据存储);最终用户(政府、医疗保健和生物技术、媒体与电信及其他);以及区域/国家/地区

云服务代理市场:当前分析与预测 (2026-2034)
服务类型侧重(集成与支持、自动化与编排、计费与配置、迁移与定制、安全与合规及其他);平台(内部经纪赋能和外部经纪赋能);部署(私有、公有和混合);企业规模(大型企业和中小企业);最终用途(IT 和电信、BFSI、政府和公共部门、医疗保健、消费品和零售、制造、能源和公用事业及其他);以及地区/国家

