Rynek przetwarzania języka naturalnego: aktualna analiza i prognoza (2021-2027)
Nacisk na typ (oparty na regułach, statystyczny, hybrydowy), zastosowanie (ekstrakcja informacji, tłumaczenie maszynowe, odpowiadanie na pytania, generowanie raportów, inne); wdrożenie (lokalne, chmura); zastosowanie (BFSI, ochrona zdrowia, IT i telekomunikacja, handel detaliczny, inne), region/kraj
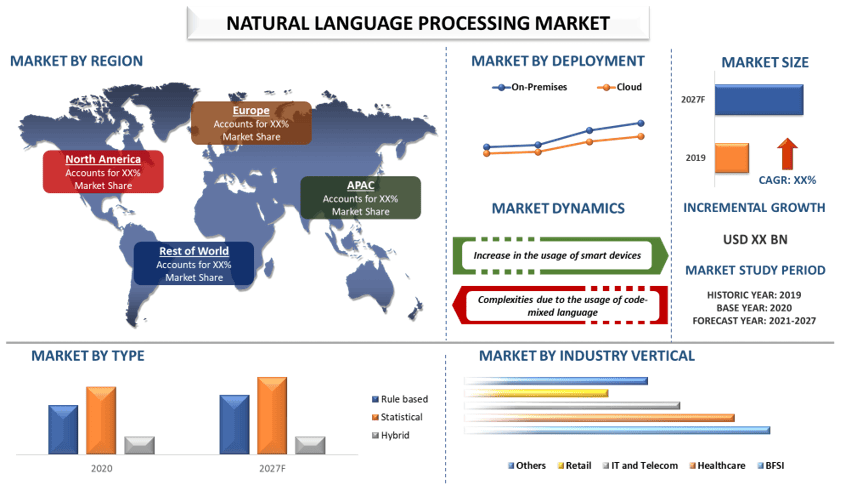
Oczekuje się, że rynek przetwarzania języka naturalnego będzie rósł w tempie CAGR na poziomie 24,% w okresie prognozowania. Oczekuje się, że rosnące wykorzystanie inteligentnych urządzeń do promowania inteligentnych środowisk wpłynie na wzrost rynku przetwarzania języka naturalnego (NLP) w okresie prognozowania. Duży popyt na oparte na chmurze rozwiązania NLP w celu obniżenia ogólnych kosztów i poprawy skalowalności ma również pobudzić wzrost rynku przetwarzania języka naturalnego (NLP). Ponadto szybka promocja analityki predykcyjnej w celu złagodzenia ryzyka i identyfikacji możliwości wzrostu może również mieć pozytywny wpływ na wzrost rynku. Ponadto oczekuje się, że szybki wzrost skali i wykorzystania IT i automatyzacji na całym świecie stworzy znaczący popyt na przetwarzanie języka naturalnego (NLP) i napędzi wzrost na rynku przetwarzania języka naturalnego (NLP). Przetwarzanie języka naturalnego wypełnia lukę komunikacyjną między technologią a ludźmi. Dzięki jego wprowadzeniu ludzie mogą teraz wydawać łatwe do zrozumienia instrukcje. Uważa się również za gałąź sztucznej inteligencji, która rozumie, interpretuje i manipuluje językami ludzkimi.
Przedstawione w raporcie spostrzeżenia
„Oczekuje się, że spośród typów segment statystyczny odnotuje najwyższy CAGR w okresie prognozowania”
Na podstawie typu rynek jest podzielony na oparty na regułach, statystyczny i hybrydowy. Oczekuje się, że segment statystyczny będzie posiadał większość rynku przetwarzania języka naturalnego. Statystyczne przetwarzanie języka naturalnego (NLP) ma na celu przeprowadzenie wnioskowania statystycznego dla dziedziny przetwarzania języka naturalnego. Statystyczne NLP umożliwia również naturalne rozmowy między chatbotami a ludźmi.
„Oczekuje się, że spośród zastosowań segment tłumaczeń maszynowych odnotuje najwyższy CAGR w okresie prognozowania”
Na podstawie zastosowania rynek jest podzielony na ekstrakcję informacji, tłumaczenie maszynowe, odpowiadanie na pytania, generowanie raportów i inne. Oczekuje się, że rynek tłumaczeń maszynowych będzie posiadał większość rynku przetwarzania języka naturalnego ze względu na rosnący popyt w organizacjach na rozwiązania, które mogą ułatwić tłumaczenie tekstu na wiele języków.
„Oczekuje się, że spośród wdrożeń segment chmurowy odnotuje najwyższy CAGR w okresie prognozowania”
Na podstawie wdrożenia rynek jest podzielony na lokalny i chmurowy. Oczekuje się, że segment chmurowy będzie posiadał większość rynku przetwarzania języka naturalnego. Oparta na chmurze platforma przetwarzania języka naturalnego umożliwia użytkownikom wykorzystywanie i analizowanie wielojęzycznych treści, treści generowanych przez użytkowników i innych treści internetowych w bardziej bezpieczny sposób oraz dostęp do tych danych z dowolnego miejsca na świecie.
„Ameryka Północna odnotuje znaczący wzrost w okresie prognozowania”
Oczekuje się, że rynek północnoamerykański odnotuje najwyższy CAGR w okresie prognozowania. Ameryka Północna jest jednym z najbardziej rozwiniętych regionów i poczyniła duże inwestycje w technologie takie jak analityka, sztuczna inteligencja i uczenie maszynowe (ML). Wiele start-upów w USA stopniowo wdraża usługi przetwarzania języka naturalnego. Ponadto wiele firm typu start-up wchodzi na rynek NLP w krajach takich jak USA. Wynika to z rosnącego popytu na produkty i rozwiązania oparte na sztucznej inteligencji i NLP, które są obecne na rynku. Jest to region generujący najwyższe przychody na globalnym rynku NLP, przy czym Stany Zjednoczone stanowią największy udział w rynku. Szybki rozwój infrastruktury i wysokie wykorzystanie technologii cyfrowych to główne czynniki napędzające wzrost rynku NLP w regionie.
Powody, dla których warto kupić ten raport:
- Badanie obejmuje analizę wielkości rynku i prognozowania zweryfikowaną przez uwierzytelnionych kluczowych ekspertów branżowych.
- Raport przedstawia szybki przegląd ogólnej kondycji branży na pierwszy rzut oka.
- Raport obejmuje dogłębną analizę wybitnych podmiotów z branży, z głównym naciskiem na kluczowe dane finansowe, portfolio produktów, strategie ekspansji i najnowsze osiągnięcia.
- Szczegółowe badanie czynników napędzających, ograniczeń, kluczowych trendów i możliwości występujących w branży.
- Badanie kompleksowo obejmuje rynek w różnych segmentach.
- Dogłębna analiza branży na poziomie regionalnym.
Opcje dostosowywania:
Globalny rynek przetwarzania języka naturalnego można dodatkowo dostosować zgodnie z wymaganiami lub dowolnym innym segmentem rynku. Poza tym UMI rozumie, że możesz mieć własne potrzeby biznesowe, dlatego nie wahaj się skontaktować z nami, aby otrzymać raport, który w pełni odpowiada Twoim wymaganiom.
Spis treści
Metodologia badań dla Globalnej Analizy Rynku Przetwarzania Języka Naturalnego (2021-2027)
Analiza historycznego rynku, szacowanie obecnego rynku i prognozowanie przyszłego rynku globalnego rynku przetwarzania języka naturalnego to trzy główne kroki podjęte w celu stworzenia i analizy adopcji przetwarzania języka naturalnego w głównych regionach na całym świecie. Przeprowadzono wyczerpujące badania wtórne w celu zebrania historycznych danych liczbowych dotyczących rynku i oszacowania obecnej wielkości rynku. Po drugie, w celu potwierdzenia tych spostrzeżeń wzięto pod uwagę liczne odkrycia i założenia. Ponadto przeprowadzono wyczerpujące wywiady pierwotne z ekspertami branżowymi w całym łańcuchu wartości globalnego rynku przetwarzania języka naturalnego. Po założeniu i walidacji danych liczbowych rynku poprzez wywiady pierwotne, zastosowaliśmy podejście top-down/bottom-up do prognozowania całkowitej wielkości rynku. Następnie przyjęto metody podziału rynku i triangulacji danych w celu oszacowania i analizy wielkości rynku segmentów i podsegmentów branży, której to dotyczy. Szczegółowa metodologia została wyjaśniona poniżej:
Analiza Historycznej Wielkości Rynku
Krok 1: Dogłębne Badanie Źródeł Wtórnych:
Przeprowadzono szczegółowe badanie wtórne w celu uzyskania historycznej wielkości rynku przetwarzania języka naturalnego za pośrednictwem wewnętrznych źródeł firmy, takich jak raporty roczne i sprawozdania finansowe, prezentacje wyników, komunikaty prasowe itp. oraz źródeł zewnętrznych, w tym czasopisma, wiadomości i artykuły, publikacje rządowe, publikacje konkurencji, raporty sektorowe, bazy danych stron trzecich i inne wiarygodne publikacje.
Krok 2: Segmentacja Rynku:
Po uzyskaniu historycznej wielkości rynku przetwarzania języka naturalnego przeprowadziliśmy szczegółową analizę wtórną w celu zebrania historycznych spostrzeżeń i udziałów w rynku dla różnych segmentów i podsegmentów dla głównych regionów. Główne segmenty zawarte w raporcie to rodzaj, aplikacja, wdrożenie i pion branżowy. Przeprowadzono dalsze analizy na poziomie krajów, aby ocenić ogólną adopcję modeli testowania w danym regionie.
Krok 3: Analiza Czynnikowa:
Po uzyskaniu historycznej wielkości rynku dla różnych segmentów i podsegmentów przeprowadziliśmy szczegółową analizę czynnikową w celu oszacowania obecnej wielkości rynku przetwarzania języka naturalnego. Ponadto przeprowadziliśmy analizę czynnikową przy użyciu zmiennych zależnych i niezależnych, takich jak różne rodzaje, aplikacje, wdrożenia i piony branżowe przetwarzania języka naturalnego. Przeprowadzono dokładną analizę scenariuszy po stronie popytu i podaży, biorąc pod uwagę najważniejsze partnerstwa, fuzje i przejęcia, ekspansję działalności i premiery produktów w sektorze rynku przetwarzania języka naturalnego na całym świecie.
Szacowanie Obecnej Wielkości Rynku i Prognoza
Określanie Obecnej Wielkości Rynku: W oparciu o przydatne spostrzeżenia z powyższych 3 kroków doszliśmy do obecnej wielkości rynku, kluczowych graczy na globalnym rynku przetwarzania języka naturalnego oraz udziałów w rynku segmentów. Wszystkie wymagane udziały procentowe i podziały rynku zostały określone przy użyciu wyżej wymienionego podejścia wtórnego i zostały zweryfikowane poprzez wywiady pierwotne.
Szacowanie i Prognozowanie: Do szacowania i prognozowania rynku przypisano wagi różnym czynnikom, w tym czynnikom napędzającym i trendom, ograniczeniom i możliwościom dostępnym dla interesariuszy. Po przeanalizowaniu tych czynników zastosowano odpowiednie techniki prognozowania, tj. podejście top-down/bottom-up, aby uzyskać prognozę rynku około 2027 roku dla różnych segmentów i podsegmentów na głównych rynkach na całym świecie. Metodologia badań przyjęta do oszacowania wielkości rynku obejmuje:
- Wielkość rynku branży pod względem przychodów (USD) i wskaźnik adopcji rynku przetwarzania języka naturalnego na głównych rynkach krajowych
- Wszystkie udziały procentowe, podziały i rozkłady segmentów i podsegmentów rynku
- Kluczowi gracze na globalnym rynku przetwarzania języka naturalnego pod względem oferowanych rozwiązań. Ponadto strategie wzrostu przyjęte przez tych graczy w celu konkurowania na szybko rozwijającym się rynku
Walidacja Wielkości i Udziału w Rynku
Badania Pierwotne: Przeprowadzono dogłębne wywiady z kluczowymi liderami opinii (Key Opinion Leaders - KOLs), w tym z kadrą kierowniczą najwyższego szczebla (CXO/VPs, Szef Działu Sprzedaży, Szef Działu Marketingu, Szef Działu Operacyjnego i Szef Regionu, Szef Krajowy itp.) w głównych regionach. Wyniki badań pierwotnych zostały następnie podsumowane i przeprowadzono analizę statystyczną w celu udowodnienia postawionej hipotezy. Dane wejściowe z badań pierwotnych zostały skonsolidowane z wynikami wtórnymi, przekształcając w ten sposób informacje w praktyczne spostrzeżenia.
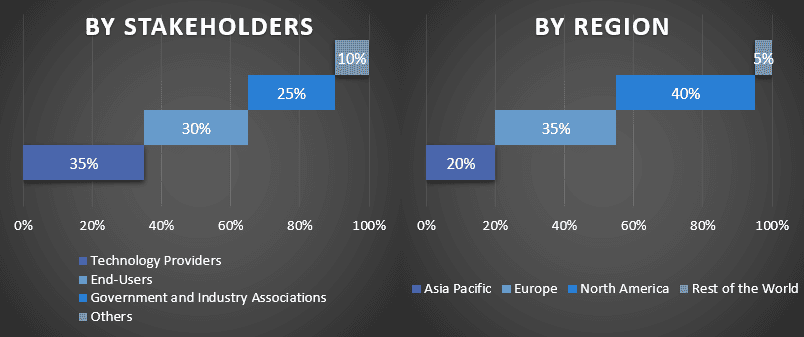
Podział Uczestników Pierwotnych w Różnych Regionach
Inżynieria Rynku
Zastosowano technikę triangulacji danych, aby zakończyć ogólne szacowanie rynku i uzyskać precyzyjne dane statystyczne dla każdego segmentu i podsegmentu globalnego rynku przetwarzania języka naturalnego. Dane zostały podzielone na kilka segmentów i podsegmentów po przestudiowaniu różnych parametrów i trendów w obszarach typu, aplikacji i wdrożenia, pionów branżowych na globalnym rynku przetwarzania języka naturalnego.
Główny cel badania globalnego rynku przetwarzania języka naturalnego
W badaniu wskazano obecne i przyszłe trendy rynkowe globalnego rynku przetwarzania języka naturalnego. Inwestorzy mogą uzyskać strategiczne spostrzeżenia, na których mogą oprzeć swoje decyzje inwestycyjne na podstawie analizy jakościowej i ilościowej przeprowadzonej w badaniu. Obecne i przyszłe trendy rynkowe określiły ogólną atrakcyjność rynku na poziomie regionalnym, zapewniając platformę dla uczestników przemysłowych do wykorzystania niewykorzystanego rynku w celu skorzystania z przewagi pioniera. Inne cele ilościowe badań obejmują:
- Analiza obecnej i prognozowanej wielkości rynku przetwarzania języka naturalnego pod względem wartości (USD). Ponadto analiza obecnej i prognozowanej wielkości rynku różnych segmentów i podsegmentów
- Segmenty w badaniu obejmują obszary typu, aplikacji, wdrożenia i pionu branżowego.
- Definiowanie i analiza ram regulacyjnych dla branży rynku przetwarzania języka naturalnego.
- Analiza łańcucha wartości związanego z obecnością różnych pośredników, wraz z analizą zachowań klientów i konkurentów w branży.
- Analiza obecnej i prognozowanej wielkości rynku przetwarzania języka naturalnego dla głównego regionu.
- Główne kraje regionów badane w raporcie obejmują Azję i Pacyfik, Europę, Amerykę Północną i resztę świata.
- Profile firm na rynku przetwarzania języka naturalnego oraz strategie wzrostu przyjęte przez uczestników rynku w celu utrzymania się na szybko rozwijającym się rynku
- Dogłębna analiza regionalna branży
Powiązane Raporty
Klienci, którzy kupili ten przedmiot, kupili również





Rynek usług IT i BPO w Indiach: bieżąca analiza i prognoza (2026-2034)
Nacisk na typ usługi (Usługi IT, Usługi BPO, Usługi inżynieryjne i R&D); typ outsourcingu (krajowy, zagraniczny, bliski zagraniczny); wielkość organizacji (Duże przedsiębiorstwa, MŚP); branża użytkownika końcowego (BFSI, IT i telekomunikacja, opieka zdrowotna, handel detaliczny i e-commerce, produkcja, inne); oraz region/stany

Rynek Technologii Gi-Fi: Aktualna Analiza i Prognoza (2025-2033)
Nacisk na rodzaj produktu (urządzenia wyświetlające i urządzenia infrastruktury sieciowej); technologię (System on chip i Integrated Circuit Chip); zastosowanie (elektronika użytkowa, komercyjne i sieciowe); oraz region/kraj

Rynek przechowywania danych w DNA: bieżąca analiza i prognoza (2026-2034)
Nacisk na Typ (Chmura i Infrastruktura Lokalna); Technologia (Sekwencyjne Przechowywanie Danych DNA i Strukturalne Przechowywanie Danych DNA); Użytkownik Końcowy (Rząd, Opieka Zdrowotna i Biotechnologia, Media i Telekomunikacja oraz Inne); oraz Region/Kraj

Rynek pośrednictwa usług chmurowych: bieżąca analiza i prognoza (2026-2034)
Nacisk na rodzaj usługi (integracja i wsparcie, automatyzacja i orkiestracja, rozliczenia i udostępnianie zasobów, migracja i dostosowywanie, bezpieczeństwo i zgodność oraz inne); platforma (wewnętrzne i zewnętrzne udostępnianie zasobów maklerskich); wdrożenie (prywatne, publiczne i hybrydowe); wielkość przedsiębiorstwa (duże przedsiębiorstwa oraz małe i średnie przedsiębiorstwa); zastosowanie końcowe (IT i telekomunikacja, BFSI, sektor publiczny i rządowy, ochrona zdrowia, towary konsumpcyjne i handel detaliczny, produkcja, energetyka i usługi komunalne oraz inne); oraz region/kraj

