Рынок наборов данных для обучения ИИ: текущий анализ и прогноз (2024–2032 гг.)
Акцент на типе (текст, аудио, изображение, видео и другие (сенсорные и геоданные)); модель развертывания (облачная и локальная); конечный пользователь (ИТ и телекоммуникации, розничная торговля и потребительские товары, здравоохранение, автомобилестроение, BFSI и другие (государственный сектор и производство)); и регион/страна
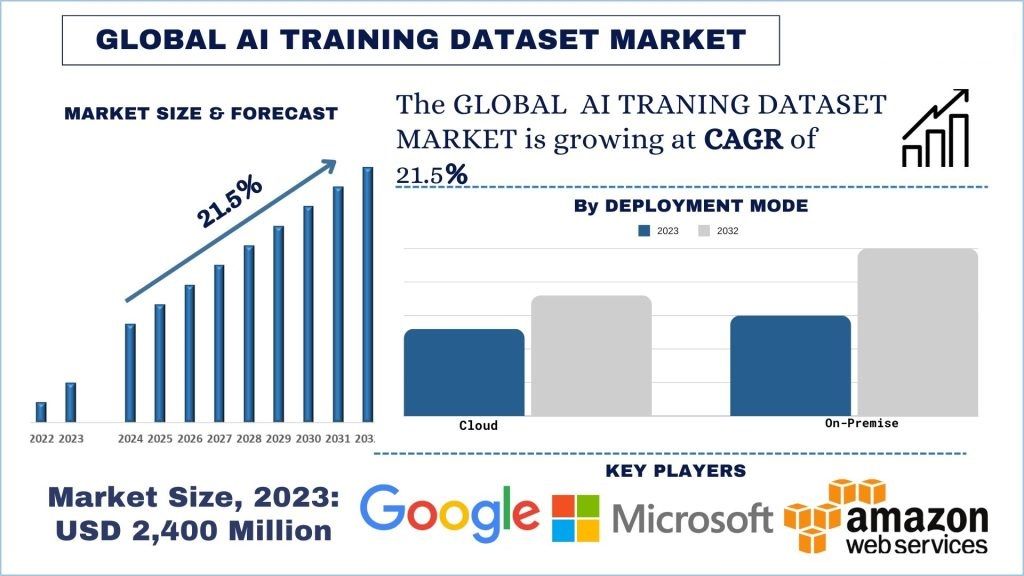
Размер и прогноз рынка наборов данных для обучения ИИ
Объем рынка наборов данных для обучения ИИ оценивался в 2 400 миллионов долларов США, и ожидается, что в течение прогнозируемого периода (2024-2032 гг.) он будет расти высокими среднегодовыми темпами роста около 21,5% благодаря растущему распространению разработки и развертывания приложений ИИ и машинного обучения.
Анализ рынка наборов данных для обучения ИИ
Наборы данных для обучения ИИ — это основные данные, используемые для обучения и разработки моделей машинного обучения и искусственного интеллекта. Эти наборы данных состоят из помеченных примеров, которые модели ИИ используют для изучения закономерностей и взаимосвязей и для точных прогнозов. Наборы данных собираются из различных источников, таких как базы данных, веб-сайты, статьи, расшифровки видео, социальные сети и другие соответствующие источники данных. Цель состоит в том, чтобы собрать разнообразный и репрезентативный набор данных. Необработанные данные тщательно маркируются и аннотируются, чтобы предоставить модели ИИ точную информацию, на основе которой она может учиться. Это включает в себя категоризацию, маркировку и описание данных.

В последние годы область искусственного интеллекта (ИИ) стала свидетелем беспрецедентного роста и достижений: приложения и технологии на базе ИИ становятся все более распространенными в различных отраслях. Это быстрое расширение ИИ привело к соответствующему всплеску спроса на высококачественные, разнообразные и всеобъемлющие наборы данных для обучения ИИ, которые позволяют этим передовым системам работать. Кроме того, растущее внедрение технологий на базе ИИ в таких секторах, как здравоохранение, финансы, электронная коммерция и транспорт, является основным фактором спроса на наборы данных для обучения ИИ. Поскольку компании и организации стремятся использовать возможности ИИ для улучшения своей деятельности, совершенствования процесса принятия решений и предоставления персонализированного опыта, потребность в надежных, достоверных и разнообразных наборах данных для обучения этих моделей ИИ резко возросла. Кроме того, растущая популярность и широкое распространение алгоритмов машинного обучения (ML) и глубокого обучения (DL) стали важным фактором резкого увеличения спроса на наборы данных для обучения ИИ. Эти передовые методы опираются на огромные объемы данных для обучения своих моделей, изучения закономерностей и составления точных прогнозов. Например, в Южной Корее данные о клиентах стали основным источником информации для обучения моделей искусственного интеллекта (ИИ) в 2022 году, о чем заявили почти 70 процентов опрошенных компаний. Кроме того, примерно 62 процента респондентов указали, что используют внутренние данные для обучения своих моделей ИИ.
Тенденции рынка наборов данных для обучения ИИ
В этом разделе обсуждаются основные тенденции рынка, которые влияют на различные сегменты рынка наборов данных для обучения ИИ, как определено нашей командой экспертов по исследованиям.
Наборы данных в текстовом формате в настоящее время используются преимущественно для обучения моделей ИИ и машинного обучения и генерируют основную часть доходов для индустрии наборов данных для обучения ИИ.
Текстовые данные широко распространены в эпоху цифровых технологий, и огромные объемы информации доступны в Интернете, в книгах, статьях, социальных сетях и различных других источниках. Текстовые наборы данных, как правило, легче собирать, хранить и обрабатывать по сравнению с другими типами данных, такими как аудио или видео. Кроме того, текстовые данные можно использовать для обучения широкого спектра моделей ИИ и машинного обучения, включая модели обработки естественного языка (NLP) для таких задач, как анализ настроений, классификация текста, генерация языка и машинный перевод. Текстовые данные также можно использовать для обучения моделей для задач, выходящих за рамки NLP, таких как обобщение документов, поиск информации и даже задачи анализа изображений и видео. Универсальность текстовых данных позволяет разрабатывать разнообразные приложения ИИ и машинного обучения, от чат-ботов и виртуальных помощников до систем рекомендаций контента и автоматизированных инструментов для письма. Кроме того, текстовые данные, как правило, менее ресурсоемки в обработке по сравнению с другими типами данных, такими как изображения или видео с высоким разрешением, которые требуют более мощного оборудования и больших вычислительных ресурсов. Это делает модели ИИ и машинного обучения на основе текста более доступными и осуществимыми для разработки и развертывания, особенно на устройствах с ограниченными ресурсами или в сценариях с ограниченной вычислительной мощностью. Такие факторы создают благоприятную среду, стимулируя всплеск спроса на текстовые наборы данных для обучения различных моделей ИИ и машинного обучения.
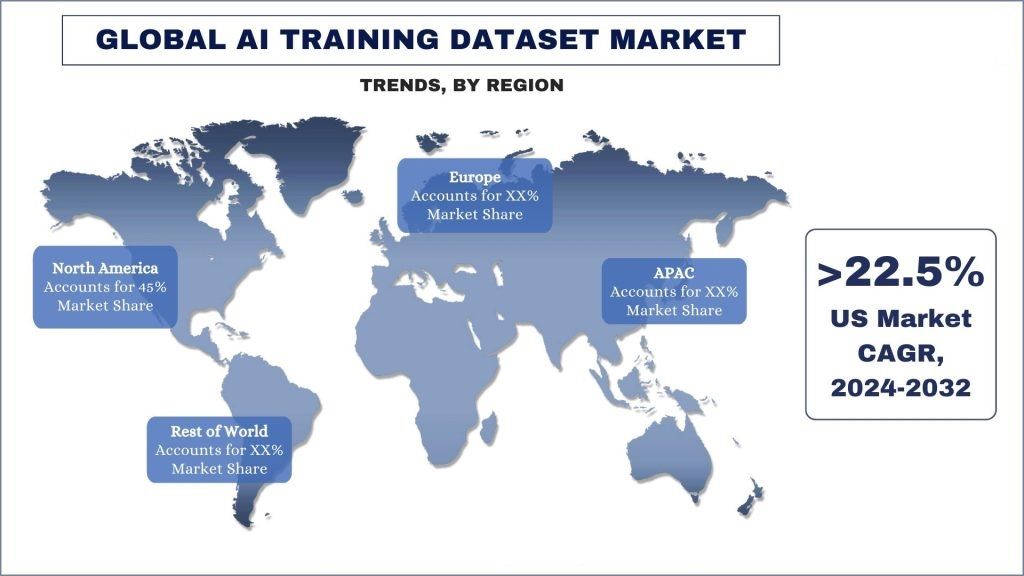
Северная Америка становится самым быстрорастущим рынком и занимает основную часть рынка наборов данных для обучения ИИ во всем мире.
Северная Америка стала одним из крупнейших и наиболее быстрорастущих рынков наборов данных для обучения ИИ. В Соединенных Штатах расположены одни из ведущих мировых исследовательских университетов, такие как Стэнфорд, Массачусетский технологический институт и Университет Карнеги-Меллона, которые добились значительных успехов в исследованиях ИИ и машинного обучения. Кроме того, известные технологические компании, в том числе Google, Microsoft и Amazon, создали передовые исследовательские лаборатории ИИ в Северной Америке, что еще больше стимулирует инновации и достижения в этой области. Кроме того, правительство США признало стратегическую важность ИИ и вложило значительные средства в поддержку исследований и разработок посредством таких инициатив, как Национальная инициатива в области искусственного интеллекта. Более того, крупные технологические компании в Северной Америке активно инвестируют в обучение и удержание лучших специалистов в области ИИ и машинного обучения, создавая самоподдерживающийся цикл инноваций и роста. Наконец, в Северной Америке, особенно в США, существует процветающая экосистема венчурного капитала, которая вкладывает миллиарды долларов в стартапы и компании, занимающиеся ИИ и машинным обучением. Присутствие крупных технологических центров, таких как Силиконовая долина, Бостон и Нью-Йорк, облегчило приток инвестиционного капитала в индустрию ИИ и машинного обучения. Например, в 2023 году, согласно данным S&P Global Market Intelligence, инвестиции в компании, занимающиеся генеративным ИИ, значительно возросли, превысив снижение общей активности в сфере слияний и поглощений. Фирмы прямых инвестиций вложили 2,18 миллиарда долларов США в генеративный ИИ, что вдвое превышает общую сумму предыдущего года. Этот всплеск капитала произошел на фоне сокращения количества сделок по слияниям и поглощениям, поддерживаемых прямыми инвестициями, в различных отраслях в 2023 году. Подобные факторы сделали Северную Америку доминирующей силой в индустрии ИИ и машинного обучения, что, следовательно, стимулирует спрос на услуги по предоставлению наборов данных для обучения ИИ для поддержки этого беспрецедентного темпа роста индустрии ИИ.
Обзор индустрии наборов данных для обучения ИИ
Рынок наборов данных для обучения ИИ является конкурентным и фрагментированным, с присутствием нескольких глобальных и международных игроков рынка. Ключевые игроки применяют различные стратегии роста для расширения своего присутствия на рынке, такие как партнерства, соглашения, сотрудничество, запуск новых продуктов, географическая экспансия, а также слияния и поглощения. Некоторые из основных игроков, работающих на рынке, — это Google, Microsoft, Amazon Web Services, Inc., IBM, Oracle, Alegion AI, Inc., TELUS International, Lionbridge Technologies, LLC, Samasource Impact Sourcing, Inc. и Appen Limited.
Новости рынка наборов данных для обучения ИИ
- 9 мая 2023 года IBM представила IBM Watsonx на своей ежегодной конференции Think. Эта новаторская платформа для ИИ и данных произведет революцию в том, как предприятия используют передовой ИИ, сохраняя при этом надежность данных. С помощью IBM Watsonx организации могут получить доступ к комплексному технологическому стеку для обучения, тонкой настройки и развертывания моделей ИИ, включая базовые модели и возможности машинного обучения. Это также обеспечивает беспрепятственное использование проверенных данных в различных облачных средах, обеспечивая скорость, управление и совместимость.
- В апреле 2024 года Baidu представила набор новых инструментов ИИ, предназначенных для того, чтобы люди без опыта программирования могли разрабатывать чат-ботов на основе генеративного ИИ, адаптированные для конкретных целей. Впоследствии эти чат-боты могут быть включены в веб-сайт, результаты поисковой системы Baidu или другие онлайн-платформы.
Охват отчета о рынке наборов данных для обучения ИИ
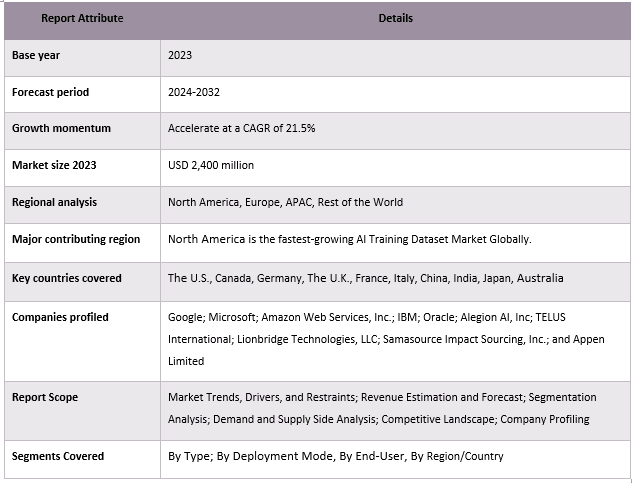
Охват отчета о рынке наборов данных для обучения ИИ
Причины купить этот отчет:
- Исследование включает в себя анализ размеров рынка и прогнозирование, проверенный проверенными ключевыми отраслевыми экспертами.
- Отчет содержит краткий обзор общих показателей отрасли с первого взгляда.
- Отчет охватывает углубленный анализ выдающихся отраслевых аналогов с основным акцентом на ключевые финансовые показатели бизнеса, портфели продуктов, стратегии расширения и последние разработки.
- Подробное изучение движущих сил, ограничений, ключевых тенденций и возможностей, преобладающих в отрасли.
- Исследование всесторонне охватывает рынок по различным сегментам.
- Глубокий анализ отрасли на региональном уровне.
Варианты настройки:
Глобальный рынок наборов данных для обучения ИИ может быть дополнительно настроен в соответствии с требованиями или любым другим сегментом рынка. Кроме того, UMI понимает, что у вас могут быть свои собственные бизнес-потребности; поэтому не стесняйтесь обращаться к нам, чтобы получить отчет, который полностью соответствует вашим требованиям.
Содержание
Методология исследования для анализа рынка наборов данных для обучения ИИ (2024-2032 гг.)
Анализ исторического рынка, оценка текущего рынка и прогнозирование будущего рынка глобального рынка наборов данных для обучения ИИ были тремя основными шагами, предпринятыми для создания и анализа внедрения наборов данных для обучения ИИ в основных регионах мира. Было проведено исчерпывающее вторичное исследование для сбора исторических данных о рынке и оценки текущего размера рынка. Во-вторых, для подтверждения этих выводов было принято во внимание множество результатов и предположений. Кроме того, были проведены исчерпывающие первичные интервью с экспертами отрасли по всей цепочке создания стоимости глобального рынка наборов данных для обучения ИИ. После предположения и подтверждения данных о рынке посредством первичных интервью мы использовали подход «сверху вниз/снизу вверх» для прогнозирования полного размера рынка. После этого были применены методы разбивки рынка и триангуляции данных для оценки и анализа размера рынка сегментов и подсегментов отрасли. Подробная методология описана ниже:
Анализ исторического размера рынка
Шаг 1: Углубленное изучение вторичных источников:
Было проведено подробное вторичное исследование для получения исторических данных о размере рынка наборов данных для обучения ИИ из внутренних источников компании, таких как годовые отчеты и финансовая отчетность, презентации о результатах деятельности, пресс-релизы и т. д., и внешних источников, включая журналы, новости и статьи, правительственные публикации, публикации конкурентов, отраслевые отчеты, сторонние базы данных и другие надежные публикации.
Шаг 2: Сегментация рынка:
После получения исторических данных о размере рынка наборов данных для обучения ИИ мы провели подробный вторичный анализ для сбора исторических данных о рынке и доле для различных сегментов и подсегментов для основных регионов. Основные сегменты, включенные в отчет, включают тип, режим развертывания и конечного пользователя. Был проведен дальнейший анализ на уровне стран для оценки общего внедрения моделей тестирования в этом регионе.
Шаг 3: Факторный анализ:
После получения исторических данных о размере рынка различных сегментов и подсегментов мы провели подробный факторный анализ для оценки текущего размера рынка наборов данных для обучения ИИ. Кроме того, мы провели факторный анализ с использованием зависимых и независимых переменных, таких как тип, режим развертывания и конечный пользователь рынка наборов данных для обучения ИИ. Был проведен тщательный анализ сценариев спроса и предложения с учетом ведущих партнерств, слияний и поглощений, расширения бизнеса и запуска продуктов в секторе рынка наборов данных для обучения ИИ по всему миру.
Оценка и прогноз текущего размера рынка
Определение текущего размера рынка: На основе действенных выводов, полученных в результате вышеуказанных 3 шагов, мы определили текущий размер рынка, ключевых игроков на глобальном рынке наборов данных для обучения ИИ и доли рынка сегментов. Все необходимые процентные доли разделения и разбивки рынка были определены с использованием вышеупомянутого вторичного подхода и были проверены посредством первичных интервью.
Оценка и прогнозирование: Для оценки и прогнозирования рынка различным факторам, включая драйверы и тенденции, ограничения и возможности, доступные для заинтересованных сторон, были присвоены веса. После анализа этих факторов были применены соответствующие методы прогнозирования, то есть подход «сверху вниз/снизу вверх», чтобы получить прогноз рынка на 2032 год для различных сегментов и подсегментов на основных рынках по всему миру. Методология исследования, принятая для оценки размера рынка, включает в себя:
- Размер рынка отрасли в стоимостном выражении (доллары США) и темпы внедрения рынка наборов данных для обучения ИИ на основных рынках внутри страны
- Все процентные доли, разделения и разбивки сегментов и подсегментов рынка
- Ключевые игроки на глобальном рынке наборов данных для обучения ИИ с точки зрения предлагаемых продуктов. Кроме того, стратегии роста, принятые этими игроками для конкуренции на быстрорастущем рынке.
Подтверждение размера и доли рынка
Первичное исследование: Были проведены углубленные интервью с ключевыми лидерами мнений (KOL), включая руководителей высшего звена (CXO/вице-президенты, руководители отдела продаж, руководители отдела маркетинга, операционные руководители, региональные руководители, главы стран и т. д.) в основных регионах. Затем результаты первичного исследования были обобщены, и был проведен статистический анализ для доказательства заявленной гипотезы. Входные данные первичного исследования были объединены с вторичными результатами, что превратило информацию в действенные выводы.
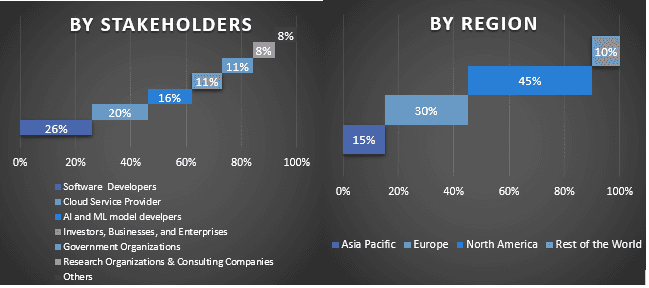
Разделение первичных участников по разным регионам
Инжиниринг рынка
Для завершения общей оценки рынка и получения точных статистических данных для каждого сегмента и подсегмента глобального рынка наборов данных для обучения ИИ была применена техника триангуляции данных. Данные были разделены на несколько сегментов и подсегментов после изучения различных параметров и тенденций в областях типа, режима развертывания и конечного пользователя на глобальном рынке наборов данных для обучения ИИ.
Основная цель исследования глобального рынка наборов данных для обучения ИИ
В исследовании были точно определены текущие и будущие рыночные тенденции глобального рынка наборов данных для обучения ИИ. Инвесторы могут получить стратегические сведения, чтобы основывать свои решения для инвестиций на качественном и количественном анализе, проведенном в исследовании. Текущие и будущие рыночные тенденции определили общую привлекательность рынка на региональном уровне, предоставив промышленному участнику платформу для использования неиспользованного рынка для получения выгоды от преимущества первопроходца. Другие количественные цели исследований включают:
- Анализ текущего и прогнозируемого размера рынка наборов данных для обучения ИИ в стоимостном выражении (доллары США). Также анализ текущего и прогнозируемого размера рынка различных сегментов и подсегментов.
- Сегменты в исследовании включают области типа, режима развертывания и конечного пользователя
- Определение и анализ нормативно-правовой базы для наборов данных для обучения ИИ
- Анализ цепочки создания стоимости с участием различных посредников, а также анализ поведения клиентов и конкурентов отрасли
- Анализ текущего и прогнозируемого размера рынка наборов данных для обучения ИИ для основного региона
- Основные страны регионов, изученные в отчете, включают Азиатско-Тихоокеанский регион, Европу, Северную Америку и остальной мир
- Профили компаний на рынке наборов данных для обучения ИИ и стратегии роста, принятые участниками рынка для поддержания устойчивости на быстрорастущем рынке.
- Углубленный анализ отрасли на региональном уровне
Часто задаваемые вопросы Часто задаваемые вопросы
Q1: Каков текущий размер рынка и потенциал роста глобального рынка наборов данных для обучения ИИ?
Q2: Какие факторы являются движущими силами роста глобального рынка наборов данных для обучения ИИ?
Q3: Какой сегмент занимает основную долю на мировом рынке наборов данных для обучения ИИ по конечному пользователю?
Q4: Каковы новые технологии и тенденции на глобальном рынке наборов данных для обучения ИИ?
Q5: Какой регион будет самым быстрорастущим на глобальном рынке наборов данных для обучения ИИ?
Q6: Кто является ключевыми игроками на глобальном рынке наборов данных для обучения ИИ?
Связанные Отчеты
Клиенты, купившие этот товар, также купили





Рынок ИТ и услуг BPO Индии: текущий анализ и прогноз (2026–2034 гг.)
Акцент на типе услуг (ИТ-услуги, услуги BPO, услуги в области инжиниринга и НИОКР); типе аутсорсинга (Onshore, Offshore, Nearshore); размере организации (крупные предприятия, МСП); отрасли конечного пользователя (BFSI, ИТ и телекоммуникации, здравоохранение, розничная торговля и электронная коммерция, производство, другие); и регионе/штатах

Рынок технологии Gi-Fi: текущий анализ и прогноз (2025-2033 гг.)
Акцент на типе продукции (устройства отображения и устройства сетевой инфраструктуры); технологии (система на кристалле и интегральная микросхема); применении (бытовая электроника, коммерция и сети); и регионе/стране

Рынок хранения данных в ДНК: текущий анализ и прогноз (2026–2034 гг.)
Акцент на типе (облачные и локальные решения); технологии (хранение данных ДНК на основе последовательностей и хранение данных ДНК на основе структуры); конечном пользователе (государственные учреждения, здравоохранение и биотехнологии, СМИ и телекоммуникации и другие); и регионе/стране

Рынок брокерских услуг в сфере облачных вычислений: текущий анализ и прогноз (2026–2034 гг.)
Акцент на типе услуг (интеграция и поддержка, автоматизация и оркестрация, биллинг и обеспечение, миграция и кастомизация, безопасность и соответствие нормативным требованиям и прочее); платформа (обеспечение внутреннего брокерского обслуживания и обеспечение внешнего брокерского обслуживания); развертывание (частное, публичное и гибридное); размер предприятия (крупные предприятия и малые и средние предприятия); конечное использование (ИТ и телекоммуникации, BFSI, государственный и общественный сектор, здравоохранение, потребительские товары и розничная торговля, производство, энергетика и коммунальные услуги и прочее); и регион/страна

