Mercado de conjuntos de datos de entrenamiento de IA: análisis actual y pronóstico (2024-2032)
Énfasis en el tipo (texto, audio, imagen, vídeo y otros [sensores y datos geográficos]); Modo de implementación (nube y local); Usuario final (TI y telecomunicaciones, venta minorista y bienes de consumo, atención médica, automotriz, BFSI y otros [gobierno y manufactura]); y región/país
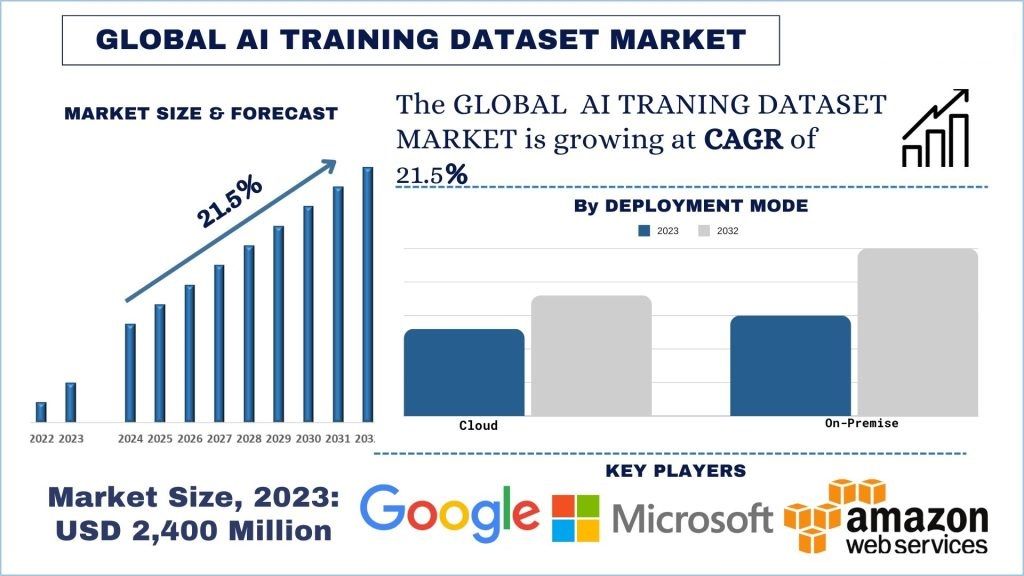
Tamaño y pronóstico del mercado de conjuntos de datos de entrenamiento de IA
El mercado de conjuntos de datos de entrenamiento de IA se valoró en USD 2400 millones y se espera que crezca a una fuerte CAGR de alrededor del 21,5% durante el período de pronóstico (2024-2032) debido a la creciente proliferación del desarrollo y la implementación de aplicaciones de IA y ML.
Análisis del mercado de conjuntos de datos de entrenamiento de IA
Los conjuntos de datos de entrenamiento de IA son los datos fundamentales utilizados para entrenar y desarrollar modelos de aprendizaje automático e inteligencia artificial. Estos conjuntos de datos consisten en ejemplos etiquetados que los modelos de IA utilizan para aprender patrones y relaciones y hacer predicciones precisas. Los conjuntos de datos se recopilan de diversas fuentes, como bases de datos, sitios web, artículos, transcripciones de video, redes sociales y otras fuentes de datos relevantes. El objetivo es recopilar un conjunto de datos diverso y representativo. Los datos brutos se etiquetan y anotan cuidadosamente para proporcionar al modelo de IA información precisa a partir de la cual aprender. Esto implica categorizar, etiquetar y describir los datos.

El campo de la Inteligencia Artificial (IA) ha sido testigo de un crecimiento y avances sin precedentes en los últimos años, con aplicaciones y tecnologías impulsadas por la IA cada vez más frecuentes en diversas industrias. Esta rápida expansión de la IA ha llevado a un aumento correspondiente en la demanda de conjuntos de datos de entrenamiento de IA de alta calidad, diversos e integrales para impulsar estos sistemas avanzados. Además, la creciente adopción de tecnologías impulsadas por la IA en sectores como la atención médica, las finanzas, el comercio electrónico y el transporte ha sido un importante impulsor de la demanda de conjuntos de datos de entrenamiento de IA. A medida que las empresas y organizaciones buscan aprovechar el poder de la IA para mejorar sus operaciones, mejorar la toma de decisiones y ofrecer experiencias personalizadas, la necesidad de conjuntos de datos robustos, confiables y diversos para entrenar estos modelos de IA se ha disparado. Además, la creciente popularidad y la adopción generalizada de los algoritmos de aprendizaje automático (ML) y aprendizaje profundo (DL) han sido un factor significativo en el aumento de la demanda de conjuntos de datos de entrenamiento de IA. Estas técnicas avanzadas se basan en vastas cantidades de datos para entrenar sus modelos, aprender patrones y hacer predicciones precisas. Por ejemplo, en Corea del Sur, los datos de los clientes surgieron como la principal fuente de información para entrenar modelos de inteligencia artificial (IA) en 2022, según lo declarado por casi el 70 por ciento de las empresas encuestadas. Además, aproximadamente el 62 por ciento de los encuestados indicaron su utilización de datos internos para entrenar sus modelos de IA.
Tendencias del mercado de conjuntos de datos de entrenamiento de IA
Esta sección analiza las principales tendencias del mercado que están influyendo en los diversos segmentos del mercado de conjuntos de datos de entrenamiento de IA, según lo identificado por nuestro equipo de expertos en investigación.
Los conjuntos de datos en formato de texto se utilizan predominantemente para el entrenamiento de modelos de IA y ML actualmente y generan la mayor parte de los ingresos para la industria de conjuntos de datos de entrenamiento de IA.
Los datos de texto son omnipresentes en la era digital, con vastas cantidades de información disponibles en Internet, en libros, artículos, redes sociales y diversas otras fuentes. Los conjuntos de datos de texto son generalmente más fáciles de recopilar, almacenar y procesar en comparación con otros tipos de datos, como audio o video. Además, los datos de texto se pueden utilizar para entrenar una amplia gama de modelos de IA y ML, incluidos los modelos de procesamiento del lenguaje natural (PNL) para tareas como el análisis de sentimientos, la clasificación de texto, la generación de lenguaje y la traducción automática. Los datos de texto también se pueden utilizar para entrenar modelos para tareas más allá de la PNL, como el resumen de documentos, la recuperación de información e incluso tareas de análisis de imágenes y videos. La versatilidad de los datos de texto permite el desarrollo de una gama diversa de aplicaciones de IA y ML, desde chatbots y asistentes virtuales hasta sistemas de recomendación de contenido y herramientas de escritura automatizadas. Además, los datos de texto generalmente requieren menos recursos computacionales para procesar en comparación con otros tipos de datos, como imágenes o videos de alta resolución, que requieren hardware más potente y mayores recursos computacionales. Esto hace que los modelos de IA y ML basados en texto sean más accesibles y factibles de desarrollar e implementar, especialmente en dispositivos con recursos limitados o en escenarios con potencia computacional limitada. Factores como estos están fomentando un entorno propicio, impulsando el aumento de la demanda de conjuntos de datos de texto para el entrenamiento de varios modelos de IA y ML.
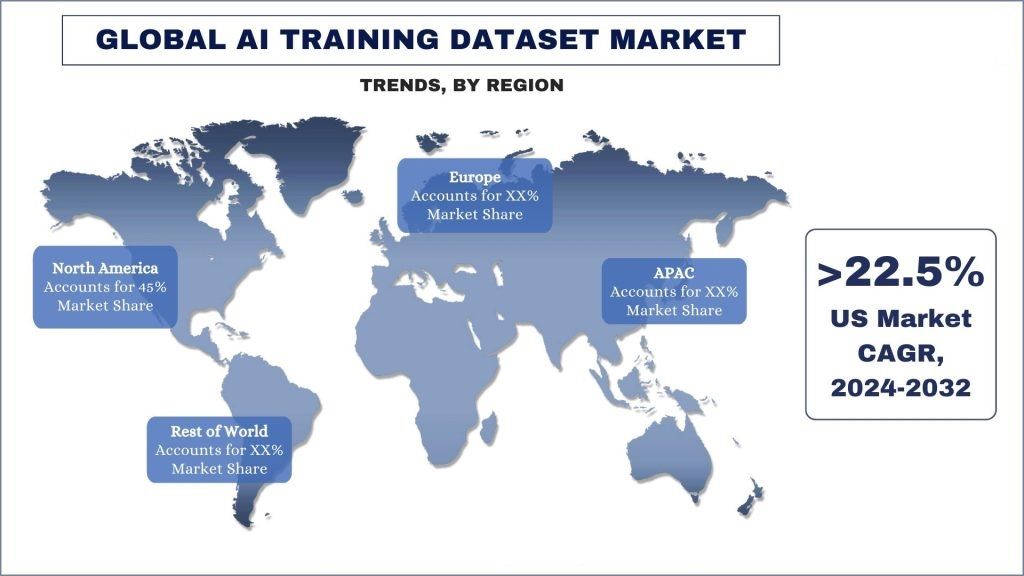
América del Norte emerge como el mercado de más rápido crecimiento y representa la mayor parte del mercado de conjuntos de datos de entrenamiento de IA a nivel mundial.
América del Norte se ha convertido en uno de los mercados más grandes y de más rápido crecimiento para conjuntos de datos de entrenamiento de IA. Estados Unidos alberga algunas de las universidades de investigación líderes en el mundo, como Stanford, el MIT y Carnegie Mellon, que han logrado avances significativos en la investigación de IA y ML. Además, importantes empresas de tecnología, como Google, Microsoft y Amazon, han establecido laboratorios de investigación de IA de vanguardia en América del Norte, lo que impulsa aún más la innovación y los avances en el campo. Además, el gobierno de EE. UU. ha reconocido la importancia estratégica de la IA y ha invertido fuertemente en apoyar la investigación y el desarrollo a través de iniciativas como la Iniciativa Nacional de Inteligencia Artificial. Además, las principales empresas de tecnología en América del Norte han estado invirtiendo activamente en capacitar y retener a los mejores talentos de IA y ML, creando un ciclo auto-reforzado de innovación y crecimiento. Por último, América del Norte, especialmente los EE. UU., alberga un próspero ecosistema de capital de riesgo que ha estado invirtiendo miles de millones de dólares en nuevas empresas y empresas de IA y ML. La presencia de importantes centros tecnológicos, como Silicon Valley, Boston y Nueva York, ha facilitado el flujo de capital de inversión hacia la industria de IA y ML. Por ejemplo, en 2023, según los datos de S&P Global Market Intelligence, las inversiones en empresas de IA generativa experimentaron un aumento significativo, superando la disminución en la actividad general de fusiones y adquisiciones. Las firmas de capital privado invirtieron USD 2.18 mil millones en IA generativa, duplicando el total del año anterior. Este aumento de capital se produjo en medio de una disminución en las transacciones de fusiones y adquisiciones respaldadas por capital privado en todas las industrias en 2023. Factores como estos han convertido a América del Norte en una fuerza predominante en la industria de IA y ML, lo que en consecuencia impulsa la demanda de servicios de conjuntos de datos de entrenamiento de IA para respaldar esta tasa de crecimiento sin precedentes de la industria de la IA.
Descripción general de la industria de conjuntos de datos de entrenamiento de IA
El mercado de conjuntos de datos de entrenamiento de IA es competitivo y fragmentado, con la presencia de varios actores del mercado globales e internacionales. Los actores clave están adoptando diferentes estrategias de crecimiento para mejorar su presencia en el mercado, como asociaciones, acuerdos, colaboraciones, lanzamientos de nuevos productos, expansiones geográficas y fusiones y adquisiciones. Algunos de los principales actores que operan en el mercado son Google, Microsoft, Amazon Web Services, Inc., IBM, Oracle, Alegion AI, Inc., TELUS International, Lionbridge Technologies, LLC, Samasource Impact Sourcing, Inc. y Appen Limited.
Noticias del mercado de conjuntos de datos de entrenamiento de IA
- IBM presentó IBM Watsonx en su conferencia anual Think el 9 de mayo de 2023. Esta innovadora plataforma de datos e IA revolucionará la forma en que las empresas utilizan la IA avanzada al tiempo que mantienen la confiabilidad de los datos. Con IBM Watsonx, las organizaciones pueden acceder a una pila de tecnología integral para entrenar, ajustar y desplegar modelos de IA, incluidos modelos fundamentales y capacidades de aprendizaje automático. También permite la utilización sin problemas de datos confiables en diferentes entornos de nube, lo que garantiza velocidad, gobernanza y compatibilidad.
- Baidu presentó en abril de 2024 un conjunto de nuevas herramientas de IA diseñadas para permitir que las personas sin experiencia en codificación desarrollen chatbots impulsados por IA generativa adaptados para fines particulares. Estos chatbots pueden incorporarse posteriormente a un sitio web, a los resultados del motor de búsqueda de Baidu u otras plataformas en línea.
Cobertura del informe de mercado de conjuntos de datos de entrenamiento de IA
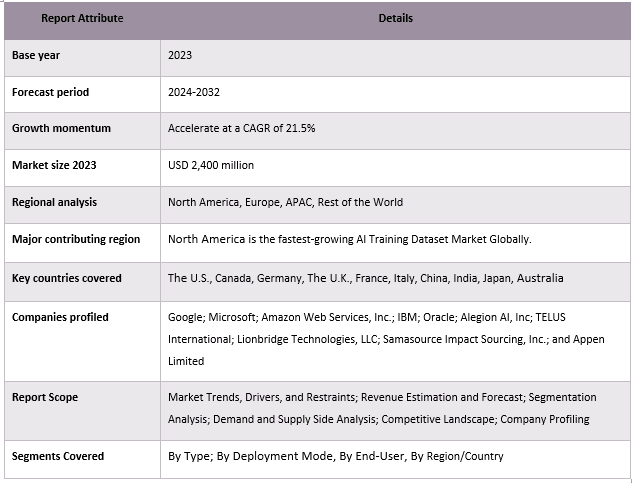
Cobertura del informe de mercado de conjuntos de datos de entrenamiento de IA
Razones para comprar este informe:
- El estudio incluye el tamaño del mercado y el análisis de pronóstico validados por expertos clave autenticados de la industria.
- El informe presenta una revisión rápida del rendimiento general de la industria de un vistazo.
- El informe cubre un análisis en profundidad de los pares prominentes de la industria con un enfoque principal en las finanzas comerciales clave, las carteras de productos, las estrategias de expansión y los desarrollos recientes.
- Examen detallado de los impulsores, las restricciones, las tendencias clave y las oportunidades que prevalecen en la industria.
- El estudio cubre exhaustivamente el mercado en diferentes segmentos.
- Análisis profundo a nivel regional de la industria.
Opciones de personalización:
El mercado global de conjuntos de datos de entrenamiento de IA se puede personalizar aún más según el requisito o cualquier otro segmento de mercado. Además de esto, UMI entiende que puede tener sus propias necesidades comerciales; por lo tanto, no dude en contactarnos para obtener un informe que se adapte completamente a sus requisitos.
Tabla de contenido
Metodología de Investigación para el Análisis del Mercado de Conjuntos de Datos de Entrenamiento de IA (2024-2032)
El análisis del mercado histórico, la estimación del mercado actual y la previsión del mercado futuro del mercado global de Conjuntos de Datos de Entrenamiento de IA fueron los tres pasos principales emprendidos para crear y analizar la adopción de conjuntos de datos de entrenamiento de IA en las principales regiones a nivel mundial. Se llevó a cabo una exhaustiva investigación secundaria para recopilar las cifras históricas del mercado y estimar el tamaño actual del mercado. En segundo lugar, para validar estos conocimientos, se tomaron en consideración numerosos hallazgos y supuestos. Además, también se realizaron exhaustivas entrevistas primarias con expertos de la industria en toda la cadena de valor del mercado global de Conjuntos de Datos de Entrenamiento de IA. Tras la suposición y validación de las cifras del mercado a través de entrevistas primarias, empleamos un enfoque de arriba hacia abajo/de abajo hacia arriba para pronosticar el tamaño completo del mercado. Posteriormente, se adoptaron métodos de desglose del mercado y triangulación de datos para estimar y analizar el tamaño del mercado de los segmentos y subsegmentos de la industria. La metodología detallada se explica a continuación:
Análisis del Tamaño del Mercado Histórico
Paso 1: Estudio en Profundidad de Fuentes Secundarias:
Se llevó a cabo un estudio secundario detallado para obtener el tamaño del mercado histórico del mercado de Conjuntos de Datos de Entrenamiento de IA a través de fuentes internas de la empresa, como informes anuales y estados financieros, presentaciones de rendimiento, comunicados de prensa, etc., y fuentes externas, incluidos revistas, noticias y artículos, publicaciones gubernamentales, publicaciones de la competencia, informes del sector, bases de datos de terceros y otras publicaciones creíbles.
Paso 2: Segmentación del Mercado:
Después de obtener el tamaño del mercado histórico del mercado de Conjuntos de Datos de Entrenamiento de IA, realizamos un análisis secundario detallado para recopilar información histórica del mercado y compartirla para diferentes segmentos y subsegmentos para las principales regiones. Los principales segmentos incluidos en el informe son el tipo, el modo de implementación y el usuario final. Además, se llevaron a cabo análisis a nivel de país para evaluar la adopción general de modelos de prueba en esa región.
Paso 3: Análisis de Factores:
Después de adquirir el tamaño del mercado histórico de diferentes segmentos y subsegmentos, llevamos a cabo un análisis de factores detallado para estimar el tamaño actual del mercado de Conjuntos de Datos de Entrenamiento de IA. Además, realizamos un análisis de factores utilizando variables dependientes e independientes como el tipo, el modo de implementación y el usuario final del mercado de Conjuntos de Datos de Entrenamiento de IA. Se realizó un análisis exhaustivo de los escenarios de demanda y oferta considerando las principales asociaciones, fusiones y adquisiciones, expansión comercial y lanzamientos de productos en el sector del mercado de Conjuntos de Datos de Entrenamiento de IA en todo el mundo.
Estimación y Previsión del Tamaño Actual del Mercado
Tamaño Actual del Mercado: Basándonos en los conocimientos prácticos de los 3 pasos anteriores, llegamos al tamaño actual del mercado, los actores clave en el mercado global de Conjuntos de Datos de Entrenamiento de IA y las cuotas de mercado de los segmentos. Todos los porcentajes de participación requeridos y los desgloses del mercado se determinaron utilizando el enfoque secundario mencionado anteriormente y se verificaron a través de entrevistas primarias.
Estimación y Previsión: Para la estimación y previsión del mercado, se asignaron ponderaciones a diferentes factores, incluidos los impulsores y tendencias, las restricciones y las oportunidades disponibles para las partes interesadas. Después de analizar estos factores, se aplicaron técnicas de previsión relevantes, es decir, el enfoque de arriba hacia abajo/de abajo hacia arriba, para llegar a la previsión del mercado para 2032 para diferentes segmentos y subsegmentos en los principales mercados a nivel mundial. La metodología de investigación adoptada para estimar el tamaño del mercado abarca:
- El tamaño del mercado de la industria, en términos de ingresos (USD) y la tasa de adopción del mercado de Conjuntos de Datos de Entrenamiento de IA en los principales mercados a nivel nacional
- Todos los porcentajes de participación, divisiones y desgloses de los segmentos y subsegmentos del mercado
- Actores clave en el mercado global de Conjuntos de Datos de Entrenamiento de IA en términos de productos ofrecidos. Además, las estrategias de crecimiento adoptadas por estos actores para competir en el mercado de rápido crecimiento.
Validación del Tamaño y la Cuota de Mercado
Investigación Primaria: Se realizaron entrevistas en profundidad con los Líderes de Opinión Clave (KOL), incluidos los Ejecutivos de Alto Nivel (CXO/VP, Jefe de Ventas, Jefe de Marketing, Jefe de Operaciones, Jefe Regional, Jefe de País, etc.) en las principales regiones. Luego, se resumieron los hallazgos de la investigación primaria y se realizó un análisis estadístico para probar la hipótesis establecida. Los aportes de la investigación primaria se consolidaron con los hallazgos secundarios, convirtiendo así la información en conocimientos prácticos.
División de Participantes Primarios en Diferentes Regiones
Ingeniería de Mercado
Se empleó la técnica de triangulación de datos para completar la estimación general del mercado y para llegar a cifras estadísticas precisas para cada segmento y subsegmento del mercado global de Conjuntos de Datos de Entrenamiento de IA. Los datos se dividieron en varios segmentos y subsegmentos después de estudiar varios parámetros y tendencias en las áreas de tipo, modo de implementación y usuario final en el mercado global de Conjuntos de Datos de Entrenamiento de IA.
El objetivo principal del Estudio del Mercado Global de Conjuntos de Datos de Entrenamiento de IA
Las tendencias actuales y futuras del mercado global de Conjuntos de Datos de Entrenamiento de IA se identificaron en el estudio. Los inversores pueden obtener información estratégica para basar su criterio para las inversiones en el análisis cualitativo y cuantitativo realizado en el estudio. Las tendencias actuales y futuras del mercado determinaron el atractivo general del mercado a nivel regional, proporcionando una plataforma para que el participante industrial explote el mercado sin explotar para beneficiarse de una ventaja de ser el primero en actuar. Otros objetivos cuantitativos de los estudios incluyen:
- Analizar el tamaño actual y previsto del mercado de Conjuntos de Datos de Entrenamiento de IA en términos de valor (USD). Además, analizar el tamaño actual y previsto del mercado de diferentes segmentos y subsegmentos.
- Los segmentos en el estudio incluyen áreas de tipo, modo de implementación y usuario final
- Definir y analizar el marco regulatorio para el Conjunto de Datos de Entrenamiento de IA
- Analizar la cadena de valor involucrada con la presencia de varios intermediarios, junto con el análisis del comportamiento de los clientes y la competencia de la industria.
- Analizar el tamaño actual y previsto del mercado de Conjuntos de Datos de Entrenamiento de IA para la región principal
- Los principales países de las regiones estudiadas en el informe incluyen Asia Pacífico, Europa, América del Norte y el resto del mundo.
- Perfiles de empresas del mercado de Conjuntos de Datos de Entrenamiento de IA y las estrategias de crecimiento adoptadas por los actores del mercado para mantenerse en el mercado de rápido crecimiento.
- Análisis regional profundo de la industria
Preguntas frecuentes Preguntas frecuentes
P1: ¿Cuál es el tamaño actual del mercado y el potencial de crecimiento del mercado global de Conjuntos de Datos de Entrenamiento de IA?
P2: ¿Cuáles son los factores impulsores del crecimiento del mercado global de conjuntos de datos de entrenamiento de IA?
P3: ¿Qué segmento posee la mayor parte del mercado global de conjuntos de datos de entrenamiento de IA por usuario final?
P4: ¿Cuáles son las tecnologías y tendencias emergentes en el mercado global de conjuntos de datos de entrenamiento de IA?
P5: ¿Qué región será el mercado de conjuntos de datos de entrenamiento de IA global de más rápido crecimiento?
P6: ¿Quiénes son los actores clave en el mercado global de Conjuntos de Datos de Entrenamiento de IA?
Relacionados Informes
Los clientes que compraron este artículo también compraron





Mercado de servicios de TI y BPO de la India: análisis actual y pronóstico (2026-2034)
Énfasis en Tipo de Servicio (Servicios de TI, Servicios de BPO, Servicios de Ingeniería e I+D); Tipo de Externalización (Onshore, Offshore, Nearshore); Tamaño de la Organización (Grandes Empresas, PYMES); Industria del Usuario Final (BFSI, TI y Telecomunicaciones, Salud, Minorista y Comercio Electrónico, Manufactura, Otros); y Región/Estados

Mercado de la tecnología Gi-Fi: Análisis actual y pronóstico (2025-2033)
Énfasis en el Tipo de Producto (Dispositivos de Visualización y Dispositivos de Infraestructura de Red); Tecnología (Sistema en chip y Chip de Circuito Integrado); Aplicación (Electrónica de Consumo, Comercial y Redes); y Región/País

Mercado de almacenamiento de datos en ADN: Análisis actual y pronóstico (2026-2034)
Énfasis en el tipo (nube y local); Tecnología (almacenamiento de datos de ADN basado en secuencias y almacenamiento de datos de ADN basado en estructuras); Usuario final (gobierno, atención médica y biotecnología, medios de comunicación y telecomunicaciones y otros); y región/país

Mercado de corretaje de servicios en la nube: análisis actual y pronóstico (2026-2034)
Énfasis en el Tipo de Servicio (Integración y Soporte, Automatización y Orquestación, Facturación y Aprovisionamiento, Migración y Personalización, Seguridad y Cumplimiento, y Otros); Plataforma (Habilitación de Corretaje Interno y Habilitación de Corretaje Externo); Implementación (Privada, Pública e Híbrida); Tamaño de la Empresa (Grandes Empresas y Pequeñas y Medianas Empresas); Uso Final (IT y Telecomunicaciones, BFSI, Gobierno y Sector Público, Atención Médica, Bienes de Consumo y Venta Minorista, Fabricación, Energía y Servicios Públicos, y Otros); y Región/País

