Rynek zbiorów danych do trenowania SI: Analiza bieżąca i prognoza (2024-2032)
Nacisk na typ (tekst, audio, obraz, wideo i inne (czujniki i dane geograficzne)); tryb wdrożenia (chmura i lokalnie); użytkownik końcowy (IT i telekomunikacja, handel detaliczny i dobra konsumpcyjne, opieka zdrowotna, motoryzacja, BFSI i inne (rząd i produkcja)); oraz region/kraj
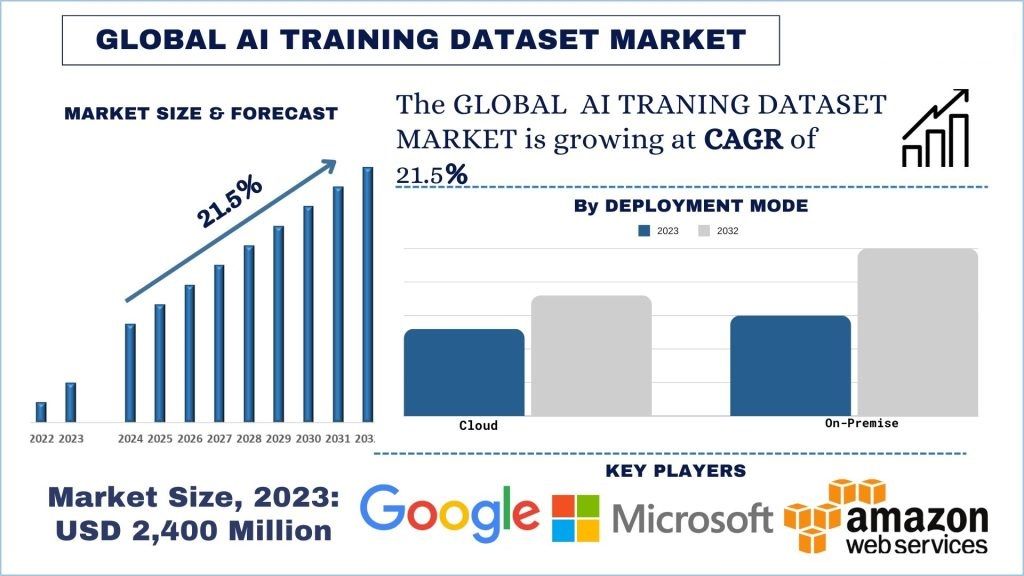
Wielkość rynku zbiorów danych do trenowania AI i prognoza
Wartość rynku zbiorów danych do trenowania AI wyniosła 2 400 milionów USD i oczekuje się, że w prognozowanym okresie (2024–2032) będzie rósł w silnym tempie CAGR wynoszącym około 21,5% ze względu na rosnące rozpowszechnienie rozwoju i wdrażania aplikacji AI i ML.
Analiza rynku zbiorów danych do trenowania AI
Zbiory danych do trenowania AI to podstawowe dane używane do trenowania i rozwijania modeli uczenia maszynowego i sztucznej inteligencji. Zbiory te składają się z oznaczonych przykładów, których modele AI używają do uczenia się wzorców i relacji oraz do tworzenia dokładnych prognoz. Zbiory danych są zbierane z różnych źródeł, takich jak bazy danych, strony internetowe, artykuły, transkrypcje wideo, media społecznościowe i inne odpowiednie źródła danych. Celem jest zebranie zróżnicowanego i reprezentatywnego zestawu danych. Surowe dane są starannie oznaczane i opisywane, aby zapewnić modelowi AI dokładne informacje, z których może się uczyć. Obejmuje to kategoryzowanie, tagowanie i opisywanie danych.

Dziedzina sztucznej inteligencji (AI) odnotowała bezprecedensowy wzrost i postęp w ostatnich latach, a aplikacje i technologie oparte na AI stają się coraz bardziej rozpowszechnione w różnych branżach. Ta szybka ekspansja AI doprowadziła do odpowiedniego wzrostu popytu na wysokiej jakości, zróżnicowane i kompleksowe zbiory danych do trenowania AI, które zasilają te zaawansowane systemy. Ponadto rosnące wykorzystanie technologii opartych na AI w sektorach takich jak opieka zdrowotna, finanse, e-commerce i transport było głównym czynnikiem napędzającym popyt na zbiory danych do trenowania AI. W miarę jak firmy i organizacje starają się wykorzystać moc AI do usprawnienia swoich operacji, poprawy podejmowania decyzji i dostarczania spersonalizowanych doświadczeń, zapotrzebowanie na solidne, niezawodne i zróżnicowane zbiory danych do trenowania tych modeli AI gwałtownie wzrosło. Dodatkowo, rosnąca popularność i powszechne stosowanie algorytmów uczenia maszynowego (ML) i głębokiego uczenia się (DL) było znaczącym czynnikiem wzrostu popytu na zbiory danych do trenowania AI. Te zaawansowane techniki opierają się na ogromnych ilościach danych do trenowania swoich modeli, uczenia się wzorców i tworzenia dokładnych prognoz. Na przykład w Korei Południowej dane klientów stały się głównym źródłem informacji do trenowania modeli sztucznej inteligencji (AI) w 2022 r., jak stwierdziło prawie 70 procent ankietowanych firm. Ponadto około 62 procent respondentów wskazało na wykorzystanie danych wewnętrznych do trenowania swoich modeli AI.
Trendy na rynku zbiorów danych do trenowania AI
Ta sekcja omawia kluczowe trendy rynkowe, które wpływają na różne segmenty rynku zbiorów danych do trenowania AI, zidentyfikowane przez nasz zespół ekspertów badawczych.
Zbiory danych w formacie tekstowym są obecnie wykorzystywane głównie do trenowania modeli AI i ML i generują znaczną część przychodów dla branży zbiorów danych do trenowania AI.
Dane tekstowe są wszechobecne w erze cyfrowej, z ogromnymi ilościami informacji dostępnych w Internecie, w książkach, artykułach, mediach społecznościowych i różnych innych źródłach. Zbiory danych tekstowych są generalnie łatwiejsze do zbierania, przechowywania i przetwarzania w porównaniu z innymi typami danych, takimi jak audio lub wideo. Ponadto dane tekstowe mogą być wykorzystywane do trenowania szerokiej gamy modeli AI i ML, w tym modeli przetwarzania języka naturalnego (NLP) do zadań takich jak analiza sentymentu, klasyfikacja tekstu, generowanie języka i tłumaczenie maszynowe. Dane tekstowe mogą być również wykorzystywane do trenowania modeli do zadań wykraczających poza NLP, takich jak streszczanie dokumentów, wyszukiwanie informacji, a nawet zadania analizy obrazów i wideo. Wszechstronność danych tekstowych pozwala na rozwój różnorodnych aplikacji AI i ML, od chatbotów i wirtualnych asystentów po systemy rekomendacji treści i zautomatyzowane narzędzia do pisania. Dodatkowo, dane tekstowe są generalnie mniej wymagające obliczeniowo w przetwarzaniu w porównaniu z innymi typami danych, takimi jak obrazy lub wideo o wysokiej rozdzielczości, które wymagają mocniejszego sprzętu i większych zasobów obliczeniowych. To sprawia, że oparte na tekście modele AI i ML są bardziej dostępne i wykonalne do opracowania i wdrożenia, zwłaszcza na urządzeniach o ograniczonych zasobach lub w scenariuszach z ograniczoną mocą obliczeniową. Czynniki takie jak te sprzyjają sprzyjającemu środowisku, napędzającemu wzrost popytu na zbiory danych tekstowych do trenowania różnych modeli AI i ML.
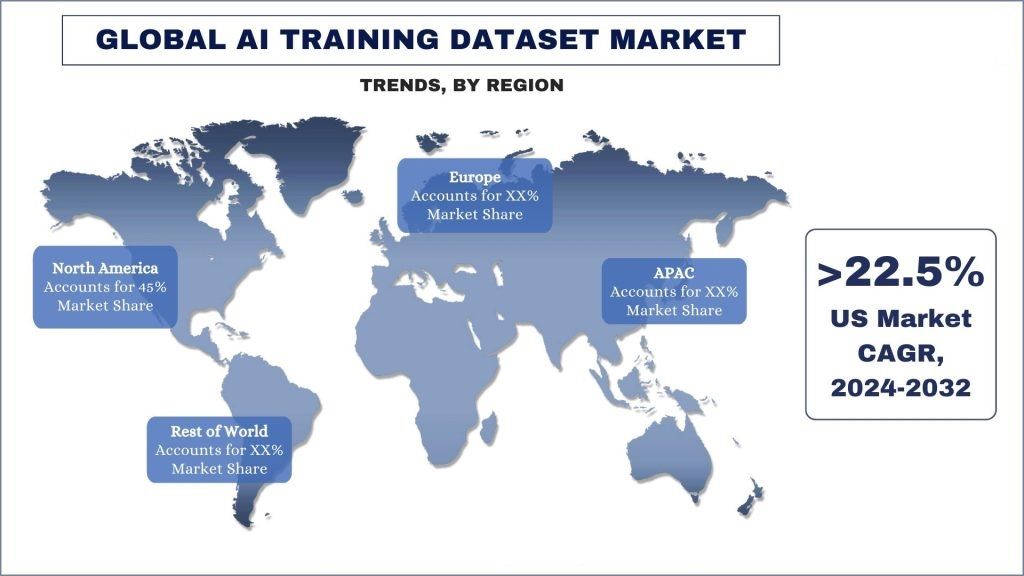
Ameryka Północna jawi się jako najszybciej rozwijający się rynek i stanowi znaczną część globalnego rynku zbiorów danych do trenowania AI.
Ameryka Północna wyłoniła się jako jeden z największych i najszybciej rozwijających się rynków dla zbiorów danych do trenowania AI. Stany Zjednoczone są domem dla jednych z wiodących na świecie uniwersytetów badawczych, takich jak Stanford, MIT i Carnegie Mellon, które dokonały znaczących postępów w badaniach nad AI i ML. Ponadto wybitne firmy technologiczne, w tym Google, Microsoft i Amazon, założyły najnowocześniejsze laboratoria badawcze AI w Ameryce Północnej, co dodatkowo napędza innowacje i postępy w tej dziedzinie. Dodatkowo, rząd USA uznał strategiczne znaczenie AI i intensywnie inwestuje we wspieranie badań i rozwoju poprzez inicjatywy takie jak National Artificial Intelligence Initiative. Co więcej, główne firmy technologiczne w Ameryce Północnej aktywnie inwestują w szkolenie i zatrzymywanie najlepszych talentów w dziedzinie AI i ML, tworząc samonapędzający się cykl innowacji i wzrostu. Wreszcie, Ameryka Północna, zwłaszcza USA, jest domem dla dobrze prosperującego ekosystemu venture capital, który wpompowuje miliardy dolarów w startupy i firmy zajmujące się AI i ML. Obecność głównych centrów technologicznych, takich jak Dolina Krzemowa, Boston i Nowy Jork, ułatwiła przepływ kapitału inwestycyjnego do branży AI i ML. Na przykład w 2023 r., według danych S&P Global Market Intelligence, inwestycje w firmy zajmujące się generatywną AI odnotowały znaczący wzrost, przewyższając spadek ogólnej aktywności fuzji i przejęć. Firmy private equity zainwestowały 2,18 miliarda USD w generatywną AI, podwajając całkowitą kwotę z poprzedniego roku. Ten wzrost kapitału nastąpił w kontekście spadku transakcji fuzji i przejęć wspieranych przez private equity w różnych branżach w 2023 r.. Czynniki takie jak te uczyniły Amerykę Północną dominującą siłą w branży AI i ML, co w konsekwencji zwiększa popyt na usługi zbiorów danych do trenowania AI w celu wspierania tego bezprecedensowego tempa wzrostu branży AI.
Przegląd branży zbiorów danych do trenowania AI
Rynek zbiorów danych do trenowania AI jest konkurencyjny i rozdrobniony, z obecnością kilku globalnych i międzynarodowych graczy rynkowych. Kluczowi gracze przyjmują różne strategie wzrostu, aby zwiększyć swoją obecność na rynku, takie jak partnerstwa, umowy, współpraca, nowe wprowadzenia produktów, ekspansje geograficzne oraz fuzje i przejęcia. Niektórzy z głównych graczy działających na rynku to Google, Microsoft, Amazon Web Services, Inc., IBM, Oracle, Alegion AI, Inc., TELUS International, Lionbridge Technologies, LLC, Samasource Impact Sourcing, Inc. i Appen Limited.
Wiadomości z rynku zbiorów danych do trenowania AI
- IBM zaprezentował IBM Watsonx na swojej corocznej konferencji Think 9 maja 2023 r. Ta przełomowa platforma AI i danych zrewolucjonizuje sposób, w jaki przedsiębiorstwa wykorzystują zaawansowaną AI, zachowując jednocześnie niezawodność danych. Dzięki IBM Watsonx organizacje mogą uzyskać dostęp do kompleksowego stosu technologii do trenowania, dostrajania i wdrażania modeli AI, w tym modeli podstawowych i możliwości uczenia maszynowego. Umożliwia również bezproblemowe wykorzystanie zaufanych danych w różnych środowiskach chmurowych, zapewniając szybkość, zarządzanie i kompatybilność.
- W kwietniu 2024 r. Baidu zaprezentowało zestaw nowych narzędzi AI zaprojektowanych, aby umożliwić osobom bez wiedzy z zakresu kodowania tworzenie chatbotów opartych na generatywnej AI, dostosowanych do konkretnych celów. Chatboty te można następnie włączyć do strony internetowej, wyników wyszukiwarki Baidu lub innych platform internetowych.
Pokrycie raportu rynku zbiorów danych do trenowania AI
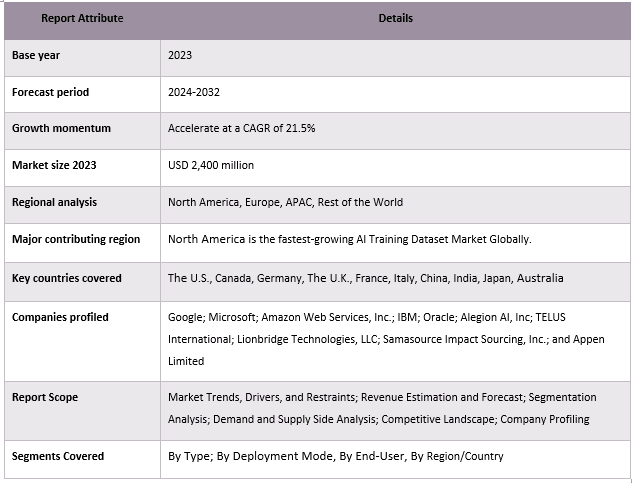
Pokrycie raportu rynku zbiorów danych do trenowania AI
Powody, dla których warto kupić ten raport:
- Badanie obejmuje analizę wielkości rynku i prognozowanie, zweryfikowaną przez uwierzytelnionych kluczowych ekspertów branżowych.
- Raport przedstawia szybki przegląd ogólnej wydajności branży na pierwszy rzut oka.
- Raport obejmuje dogłębną analizę wybitnych podmiotów branżowych, z głównym naciskiem na kluczowe dane finansowe, portfele produktów, strategie ekspansji i najnowsze wydarzenia.
- Szczegółowe badanie czynników napędzających, ograniczeń, kluczowych trendów i możliwości występujących w branży.
- Badanie kompleksowo obejmuje rynek w różnych segmentach.
- Dogłębna analiza branży na poziomie regionalnym.
Opcje dostosowywania:
Globalny rynek zbiorów danych do trenowania AI można dodatkowo dostosować zgodnie z wymaganiami lub dowolnym innym segmentem rynku. Poza tym UMI rozumie, że możesz mieć własne potrzeby biznesowe; dlatego skontaktuj się z nami, aby otrzymać raport, który w pełni odpowiada Twoim wymaganiom.
Spis treści
Metodologia badań do analizy rynku zbiorów danych do trenowania sztucznej inteligencji (2024-2032)
Analiza historycznego rynku, szacowanie bieżącego rynku i prognozowanie przyszłego rynku globalnego rynku zbiorów danych do trenowania sztucznej inteligencji to trzy główne kroki podjęte w celu stworzenia i analizy adopcji zbiorów danych do trenowania sztucznej inteligencji w głównych regionach na całym świecie. Przeprowadzono wyczerpujące badania wtórne w celu zebrania danych liczbowych z historycznego rynku i oszacowania bieżącej wielkości rynku. Po drugie, aby zweryfikować te spostrzeżenia, wzięto pod uwagę liczne ustalenia i założenia. Ponadto przeprowadzono również wyczerpujące wywiady pierwotne z ekspertami branżowymi w całym łańcuchu wartości globalnego rynku zbiorów danych do trenowania sztucznej inteligencji. Po założeniu i zatwierdzeniu danych liczbowych rynku poprzez wywiady pierwotne; zastosowaliśmy podejście odgórne/oddolne do prognozowania całkowitej wielkości rynku. Następnie przyjęto metody podziału rynku i triangulacji danych w celu oszacowania i analizy wielkości rynku segmentów i podsegmentów branży. Szczegółowa metodologia została wyjaśniona poniżej:
Analiza historycznej wielkości rynku
Krok 1: Dogłębne badanie źródeł wtórnych:
Przeprowadzono szczegółowe badanie wtórne w celu uzyskania historycznej wielkości rynku zbiorów danych do trenowania sztucznej inteligencji za pośrednictwem wewnętrznych źródeł firmy, takich jak raporty roczne i sprawozdania finansowe, prezentacje wyników, komunikaty prasowe itp., oraz źródeł zewnętrznych, w tym czasopism, wiadomości i artykułów, publikacji rządowych, publikacji konkurencji, raportów sektorowych, baz danych stron trzecich i innych wiarygodnych publikacji.
Krok 2: Segmentacja rynku:
Po uzyskaniu historycznej wielkości rynku zbiorów danych do trenowania sztucznej inteligencji przeprowadziliśmy szczegółową analizę wtórną w celu zebrania historycznych spostrzeżeń rynkowych i udziału dla różnych segmentów i podsegmentów dla głównych regionów. Główne segmenty zawarte w raporcie to typ, tryb wdrożenia i użytkownik końcowy. Przeprowadzono dalsze analizy na poziomie krajowym w celu oceny ogólnej adopcji modeli testowych w danym regionie.
Krok 3: Analiza czynnikowa:
Po uzyskaniu historycznej wielkości rynku różnych segmentów i podsegmentów przeprowadziliśmy szczegółową analizę czynnikową w celu oszacowania bieżącej wielkości rynku zbiorów danych do trenowania sztucznej inteligencji. Ponadto przeprowadziliśmy analizę czynnikową przy użyciu zmiennych zależnych i niezależnych, takich jak typ, tryb wdrożenia i użytkownik końcowy rynku zbiorów danych do trenowania sztucznej inteligencji. Przeprowadzono dogłębną analizę scenariuszy popytu i podaży, biorąc pod uwagę czołowe partnerstwa, fuzje i przejęcia, ekspansję biznesową i wprowadzenie produktów na rynek w sektorze rynku zbiorów danych do trenowania sztucznej inteligencji na całym świecie.
Szacowanie i prognozowanie bieżącej wielkości rynku
Określanie bieżącej wielkości rynku: W oparciu o użyteczne informacje z powyższych 3 kroków doszliśmy do wniosków na temat bieżącej wielkości rynku, kluczowych graczy na globalnym rynku zbiorów danych do trenowania sztucznej inteligencji i udziałów w rynku poszczególnych segmentów. Wszystkie wymagane udziały procentowe i podziały rynku zostały określone przy użyciu wspomnianego powyżej podejścia wtórnego i zostały zweryfikowane poprzez wywiady pierwotne.
Szacowanie i prognozowanie: Do oszacowania i prognozowania rynku przypisano wagi różnym czynnikom, w tym czynnikom napędzającym i trendom, ograniczeniom i możliwościom dostępnym dla interesariuszy. Po przeanalizowaniu tych czynników zastosowano odpowiednie techniki prognozowania, tj. podejście odgórne/oddolne, aby uzyskać prognozę rynkową na rok 2032 dla różnych segmentów i podsegmentów na głównych rynkach na całym świecie. Metodologia badań przyjęta do oszacowania wielkości rynku obejmuje:
- Wielkość rynku branży pod względem przychodów (USD) i wskaźnik adopcji rynku zbiorów danych do trenowania sztucznej inteligencji na głównych rynkach krajowych
- Wszystkie udziały procentowe, podziały i podziały segmentów i podsegmentów rynku
- Kluczowi gracze na globalnym rynku zbiorów danych do trenowania sztucznej inteligencji pod względem oferowanych produktów. Ponadto strategie rozwoju przyjęte przez tych graczy w celu konkurowania na szybko rozwijającym się rynku.
Walidacja wielkości i udziału w rynku
Badania pierwotne: Przeprowadzono dogłębne wywiady z kluczowymi liderami opinii (KOL), w tym z kadrą kierowniczą wyższego szczebla (CXO/VP, kierownik ds. sprzedaży, kierownik ds. marketingu, kierownik ds. operacyjnych, kierownik regionalny, kierownik krajowy itp.) w głównych regionach. Następnie podsumowano wyniki badań pierwotnych i przeprowadzono analizę statystyczną w celu udowodnienia postawionej hipotezy. Dane wejściowe z badań pierwotnych zostały połączone z wynikami badań wtórnych, co przekształciło informacje w praktyczne spostrzeżenia.
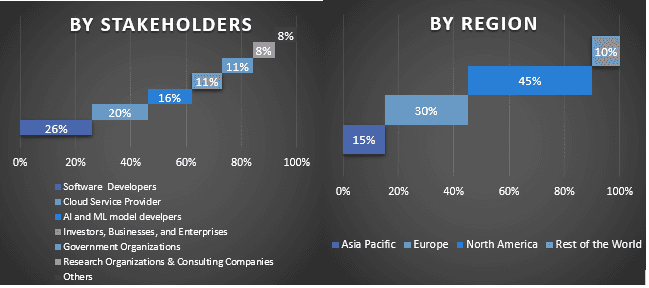
Podział uczestników badań pierwotnych w różnych regionach
Inżynieria rynku
Zastosowano technikę triangulacji danych, aby ukończyć ogólne szacowanie rynku i uzyskać dokładne dane statystyczne dla każdego segmentu i podsegmentu globalnego rynku zbiorów danych do trenowania sztucznej inteligencji. Dane zostały podzielone na kilka segmentów i podsegmentów po przestudiowaniu różnych parametrów i trendów w obszarach typu, trybu wdrożenia i użytkownika końcowego na globalnym rynku zbiorów danych do trenowania sztucznej inteligencji.
Główny cel badania globalnego rynku zbiorów danych do trenowania sztucznej inteligencji
W badaniu wskazano obecne i przyszłe trendy rynkowe na globalnym rynku zbiorów danych do trenowania sztucznej inteligencji. Inwestorzy mogą uzyskać strategiczne informacje, aby oprzeć swoje decyzje inwestycyjne na analizie jakościowej i ilościowej przeprowadzonej w badaniu. Obecne i przyszłe trendy rynkowe określiły ogólną atrakcyjność rynku na poziomie regionalnym, zapewniając uczestnikowi przemysłowemu platformę do wykorzystania niewykorzystanego rynku w celu skorzystania z przewagi pioniera. Inne cele ilościowe badań obejmują:
- Analizę obecnej i prognozowanej wielkości rynku zbiorów danych do trenowania sztucznej inteligencji pod względem wartości (USD). Ponadto należy przeanalizować obecną i prognozowaną wielkość rynku różnych segmentów i podsegmentów.
- Segmenty w badaniu obejmują obszary typu, trybu wdrożenia i użytkownika końcowego
- Zdefiniowanie i analizę ram regulacyjnych dla zbiorów danych do trenowania sztucznej inteligencji
- Analizę łańcucha wartości związanego z obecnością różnych pośredników, wraz z analizą zachowań klientów i konkurentów w branży
- Analizę obecnej i prognozowanej wielkości rynku zbiorów danych do trenowania sztucznej inteligencji dla głównego regionu
- Główne kraje regionów badane w raporcie to Azja i Pacyfik, Europa, Ameryka Północna i reszta świata
- Profile firm na rynku zbiorów danych do trenowania sztucznej inteligencji oraz strategie rozwoju przyjęte przez uczestników rynku w celu utrzymania się na szybko rozwijającym się rynku.
- Dogłębna analiza branży na poziomie regionalnym
Najczęściej zadawane pytania FAQ
P1: Jaka jest obecna wielkość rynku i potencjał wzrostu globalnego rynku zbiorów danych do trenowania sztucznej inteligencji?
P2: Jakie są czynniki napędzające wzrost globalnego rynku zbiorów danych do szkolenia AI?
P3: Który segment posiada największą część globalnego rynku zestawów danych do trenowania AI pod względem użytkownika końcowego?
P4: Jakie są wschodzące technologie i trendy na globalnym rynku zbiorów danych do uczenia AI?
P5: Który region będzie najszybciej rozwijającym się globalnym rynkiem zbiorów danych do trenowania AI?
P6: Kim są kluczowi gracze na globalnym rynku zbiorów danych treningowych AI?
Powiązane Raporty
Klienci, którzy kupili ten przedmiot, kupili również





Rynek usług IT i BPO w Indiach: bieżąca analiza i prognoza (2026-2034)
Nacisk na typ usługi (Usługi IT, Usługi BPO, Usługi inżynieryjne i R&D); typ outsourcingu (krajowy, zagraniczny, bliski zagraniczny); wielkość organizacji (Duże przedsiębiorstwa, MŚP); branża użytkownika końcowego (BFSI, IT i telekomunikacja, opieka zdrowotna, handel detaliczny i e-commerce, produkcja, inne); oraz region/stany

Rynek Technologii Gi-Fi: Aktualna Analiza i Prognoza (2025-2033)
Nacisk na rodzaj produktu (urządzenia wyświetlające i urządzenia infrastruktury sieciowej); technologię (System on chip i Integrated Circuit Chip); zastosowanie (elektronika użytkowa, komercyjne i sieciowe); oraz region/kraj

Rynek przechowywania danych w DNA: bieżąca analiza i prognoza (2026-2034)
Nacisk na Typ (Chmura i Infrastruktura Lokalna); Technologia (Sekwencyjne Przechowywanie Danych DNA i Strukturalne Przechowywanie Danych DNA); Użytkownik Końcowy (Rząd, Opieka Zdrowotna i Biotechnologia, Media i Telekomunikacja oraz Inne); oraz Region/Kraj

Rynek pośrednictwa usług chmurowych: bieżąca analiza i prognoza (2026-2034)
Nacisk na rodzaj usługi (integracja i wsparcie, automatyzacja i orkiestracja, rozliczenia i udostępnianie zasobów, migracja i dostosowywanie, bezpieczeństwo i zgodność oraz inne); platforma (wewnętrzne i zewnętrzne udostępnianie zasobów maklerskich); wdrożenie (prywatne, publiczne i hybrydowe); wielkość przedsiębiorstwa (duże przedsiębiorstwa oraz małe i średnie przedsiębiorstwa); zastosowanie końcowe (IT i telekomunikacja, BFSI, sektor publiczny i rządowy, ochrona zdrowia, towary konsumpcyjne i handel detaliczny, produkcja, energetyka i usługi komunalne oraz inne); oraz region/kraj

